Seq2Seq
- encoder, decoder구조로 이루어진 모델이다.
- RNN기반의 모델 구조 이기 때문에 hidden state의 dim이 고정된 상태로 계속해서 정보를 누적한다. 길이가 짧은 때는 괜찮지만 길어지게 되면 앞부분의 정보를 잃을 수 있다.
- decoder에서는 SoS가 들어오면 encoder의 최종 output을 고려해 첫 단어를 생성해야하는데 위와 같은 문제로 encoder의 앞부분 정보를 잃어 첫 단어부터 제대로 생성할 수 없을 수 있다.
- 문제를 해결하기위해 attention module을 사용한다. attention module은 decoder의 hidden state하나와 encoder 의 각 time step의 hidden state를 입력을 받아 현재 decoder에서 어떤 time step의 encoder hidden state를 어느정도 사용할지 encoder state vector의 가중평균을 구해준다.
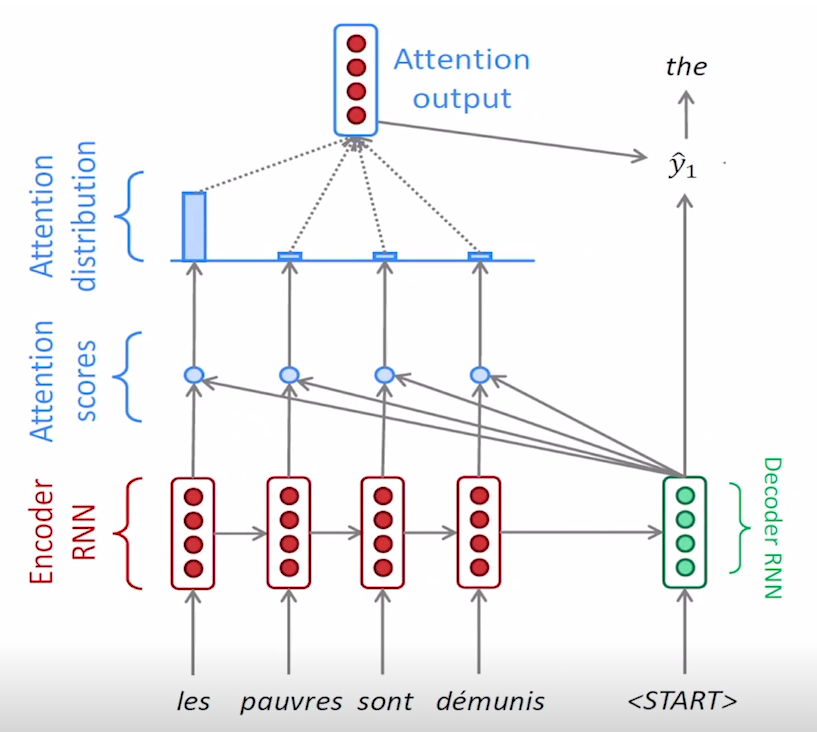
- Decoder의 hidden state와 Encoder의 각 time step의 hidden state유사도를 구한다. 이후 softmax를 취해 각 hidden state의 비율을 알 수 있는데 이러한 벡터를 attention vector라 한다.(위의 그림에서 Attention distribution vector)
- Attention Score(유사도) 구하는 방법
- 단순히 두 vector의 내적으로 계산하는 방법 $score(h_t, \bar{h_s})=h_t^T\bar{h_s}$
- Attention score를 구할 때 단순히 내적을 취하는 것이 아닌 학습 가능한 행렬을 추가하는 방법 $score(h_t,\bar{h}_s)=h_t^TW_a\bar{h_s}$
- 두 hidden state를 concat하여 FC Layer의 입력으로 넣어 유사도를 구하는 Concat기반 방법 $score(h_t, \bar{h_s})=v_a^Ttanh(W_a[h_t;\bar{h_s}])$
- Attention Score(유사도) 구하는 방법
- attention module의 output vector(context vector)와 Decoder의 hidden state vector가 concat되어서 output layer의 input으로 들어가 단어를 예측한다.
- Teacher forcing : 학습을 진행할 때 Decoder의 input으로 이전 time step의 output을 넣어주지 않고 실제 label값을 넣어주는 방법이다.
Greedy decoding
- 일반적인 seq2seq with attention에서는 현재 time step에서 가장 높은 확률을 가지는 단어 하나를 생성 하는 Greedy decoding이다. 이러한 Greedy decoding 방법은 이전에 생성한 결과를 바꿀 수 없다.
- 입력문장을 x, 출력 문장을 y라고하고 출력문장의 첫번째 단어를 $y_1$이라고 생각하면 아래와 같이 확률을 구할 수 있다.
- 위의 식을 보면 첫번째 단어를 높은 확률인 단어를 선택했지만 뒤로 진행됨에 따라 전체적인 확률이 높지 않을 수 있다. 현재 단어에 대한 확률값이 조금 낮지만 전체적인 확률값이 높아지도록 선택하는 것이 좋은 결과를 얻을 수 있다. 하지만 모든 경우의 수를 구하기 위해서는 경우의 수가 너무 많아 불가능하다.
- 하나의 time step만 사용하는 greedy decoding 방법과 모든 time step의 경우를 다 따져보는 두가지 방법을 적절하게 사용한것이 Beam search이다.
Beam search
- beam search는 디코더의 각 time step마다 k개의 가능한 경우를 고려해 최종 k(beam size) 개의 output중에서 가장 확률이 높은것을 선택하는 방식이다. (보통 beam size는 5 ~ 10)
- k개의 출력은 hypothesis라고 한다. 각 확률을 곱하는것으로 각 hypothesis의 확률을 구해야하지만 log를 사용해 더하는것으로 계산할 수 있다.
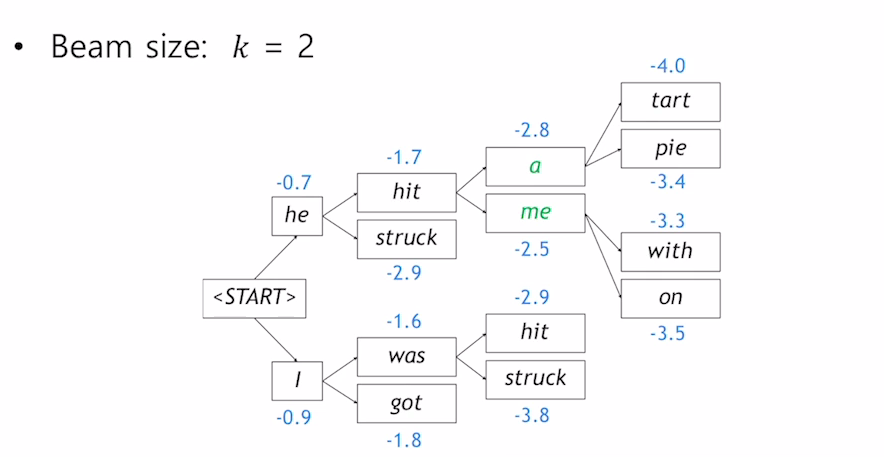
- 가장 높은 확률을 가지는 k개를 계속해서 업데이트 해서 가져간다. 위의 예에서 처음 문장을 생성할 때 가장 확률이 높은 2개 he, i가 선택되고 다음 time step에서는 he, i에서 각각 가장 확률이 높은 2개씩을 선택해 확률을 계산하고 가장 확률이 높은 2개를 사용한다.
- beam search decoding에서는 각 hypothesis가 다른 timestep에
로 문장을 끝낼 수 있다 이런 경우 임시 저장해놓고 위의 과정을 계속 반복한다. (completed hypothesis) - beam search decoding 종료시기
- 미리 정해놓은 timestep T까지 도달할 때 종료
- 저장해놓은 완성본이 n개 이상이 되었을 때 종료
- completed hypothesis중에서 선택을 해야하는데 길이가 짧을 수록 확률이 높게 나오기 떄문에 Normalize를 해주어야한다.
문장 번역 평가 방법
실제 결과와 예측결과를 단순 위치 기반으로 구분하게되면 정확한 정확도를 계산할 수 없다.
예를들어 I love you와 oh i love you의 경우 위치 기반으로 구분하면 0%의 결과가 나온다.
- precision 방법(정밀도)
- 예측 문장에서 위치를 고려하지 않고 정답 문장과 일치하는 단어의 수를 예측 문장의 단어의 수로 나누어 주는것으로 계산
- $precision = \frac{correct word}{length_of_prediction}$
- recall 방법(재현율)
- 분자는 precision방법과 똑같지만 분모로 예측결과의 길이가 아닌 정답의 길이를 사용한다.
- $recall=\frac{correctword}{length_of_reference}$
- F measure
- precision, recall의 조화 평균을 사용한다.
- $F-measure = \frac{precision *recall}{\frac{1}{2}(precision+recall)}$
이러한 방법들은 단어의 위치를 전혀 고려하지 않기 때문에 문법적으로 맞지 않지만 특정 단어들이 포함되어만 있으면 높은 정확도로 계산된다.
BLEU score(BiLingual Evaluation Understudy)
- N-gram overlap (n개의 연속된 단어)를 사용한다.
- 4개의 (1 ~ 4 N-gram) precision의 기하평균을 사용한다.
