object detection
instance segmentation
![Detection0]()
Panoptic segmentation
![Detection1]()


Anchor boxes
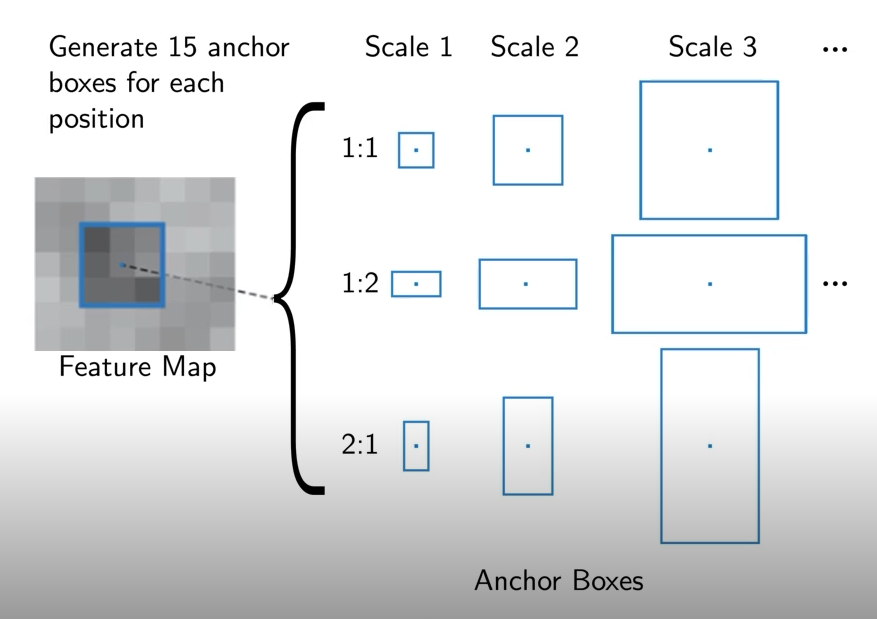
- 각 위치에서 발생할 것 같은 박스들을 미리 정의해둔 후보군
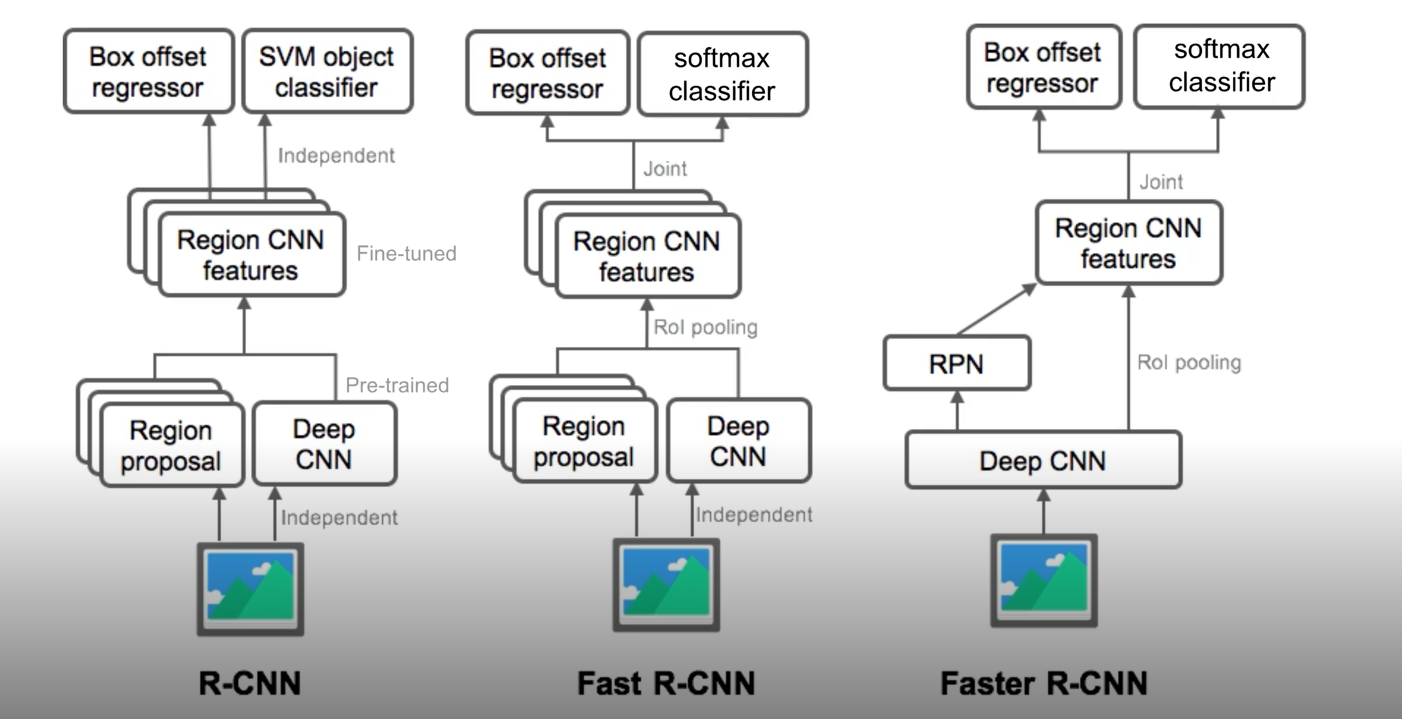
Two stage detector
- R-CNN
- region Proposal를 만들고 적정 size로 warping 한 뒤 pretrain된 CNN모델에 입력으로 주어 Claassify한다.
- 단점
- 각 region proposal마다 모델의 입력으로 넣어야해서 시간이 오래걸린다.
- selective search같은 알고리즘으로 region proposal을 찾기 때문에 데이터가 많아도 성능 향상에 한계가 있다.
- Fast R-CNN
- 원본 이미지를 Conv Layer를 통해 feature map을 만든다.
- Feature Map으 로부터 RoI(Region of interest) Pooling으로 RoI를 얻는다.
- 얻어지는 각각의 RoI로 class, box prediction을 수행한다.
- 단점
- R-CNN과 마찬가지로 object를 selective search로 찾는다.
- Faster R-CNN
- Anchor boxes를 사용
- Ground truth와 IoU가 0.7이상이면 positive
- Ground truth와 IoU가 0.3이하이면 negative
- NMS(Non Maximum Suppression)
- 바운딩 박스를 필터링하기 위해서 사용
- 가장 높은 objectiveness score를 가진 box를 선택한다.
- 다른 box들과 IoU를 계산한다.
- IoU가 50%이상인 box를 지운다.
- 다음으로 높은 박스를 찾는다.
- 바운딩 박스를 필터링하기 위해서 사용
- Anchor boxes를 사용
One Stage Detector
- YOLO
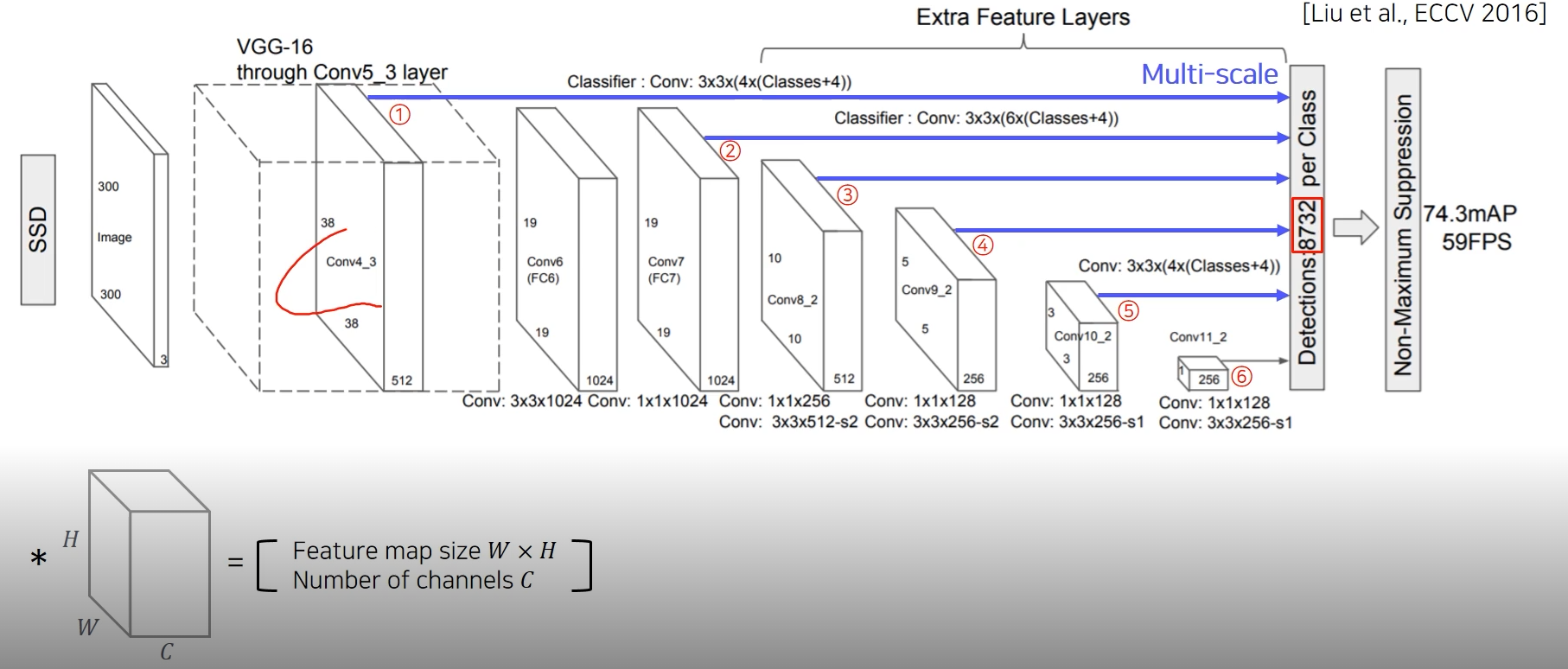
SSD(single shot multibox Dector
![Detection4]()
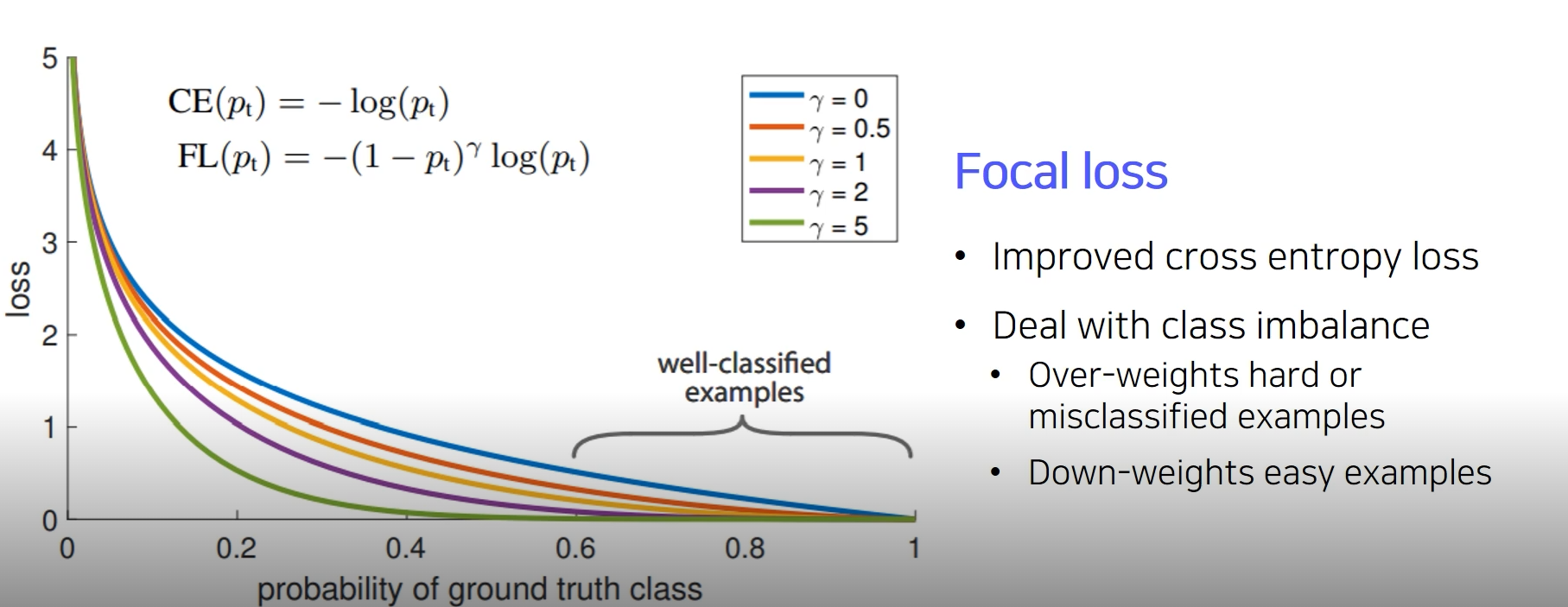
Focal Loss
- Single stage detector 에서는 RoI Polling이 없기 때문에 모든 영역에서의 loss를 계산한다. 대부분 background의 영역이 훨씬 많기 때문에 Positive sample에 비해 negative sample가 너무 많아 Class Imbalance문제를 발생시킨다.
Class Imbalance를 해결하기 위해 Focal loss가 등장
![Detection5]()
- Cross Entropy의 확장이라고 생각하면 된다.
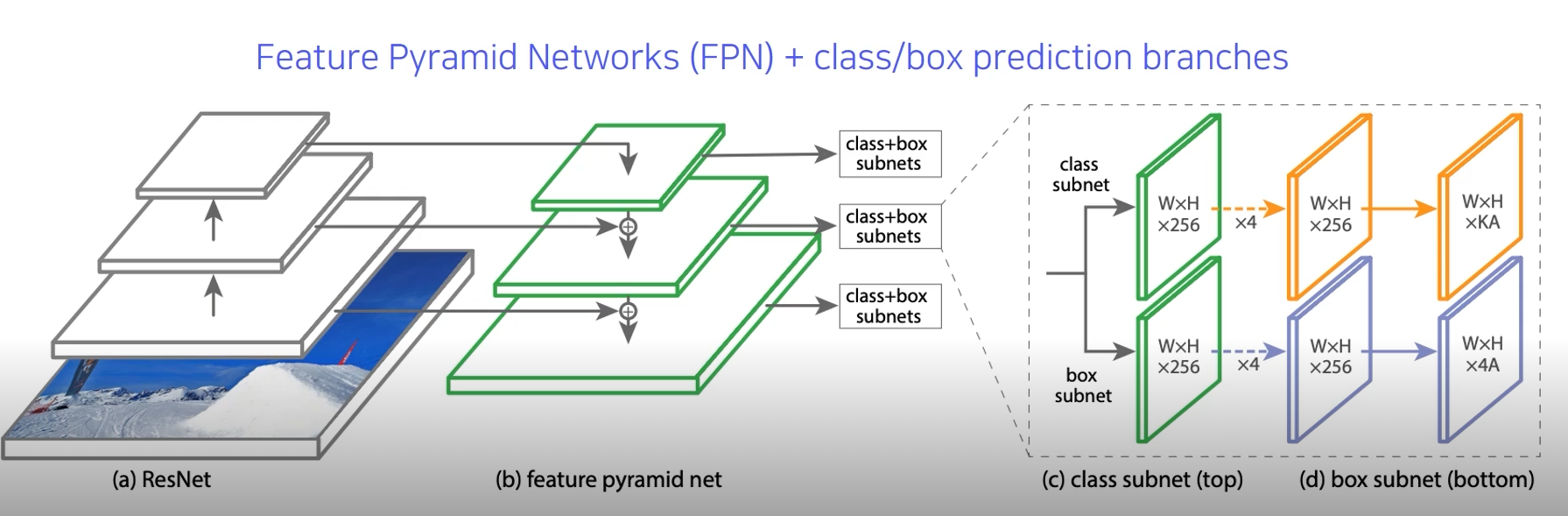
RetinaNet
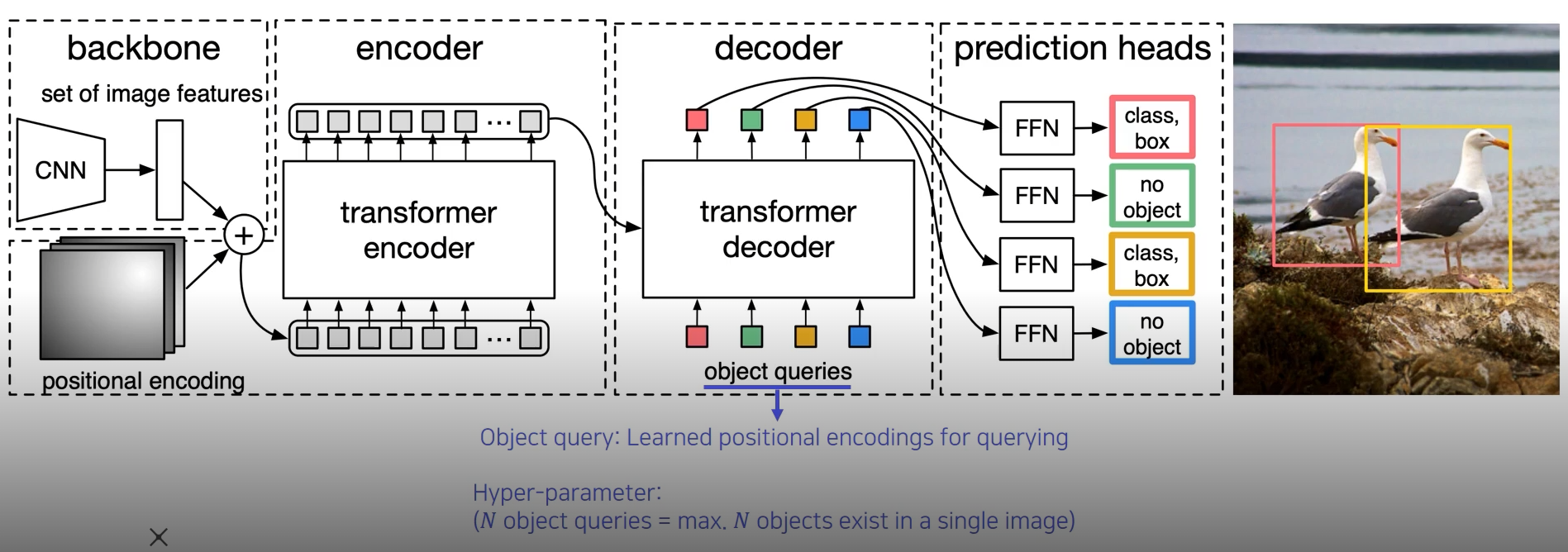
DETR (Detection with Transformer)
CNN visualizing
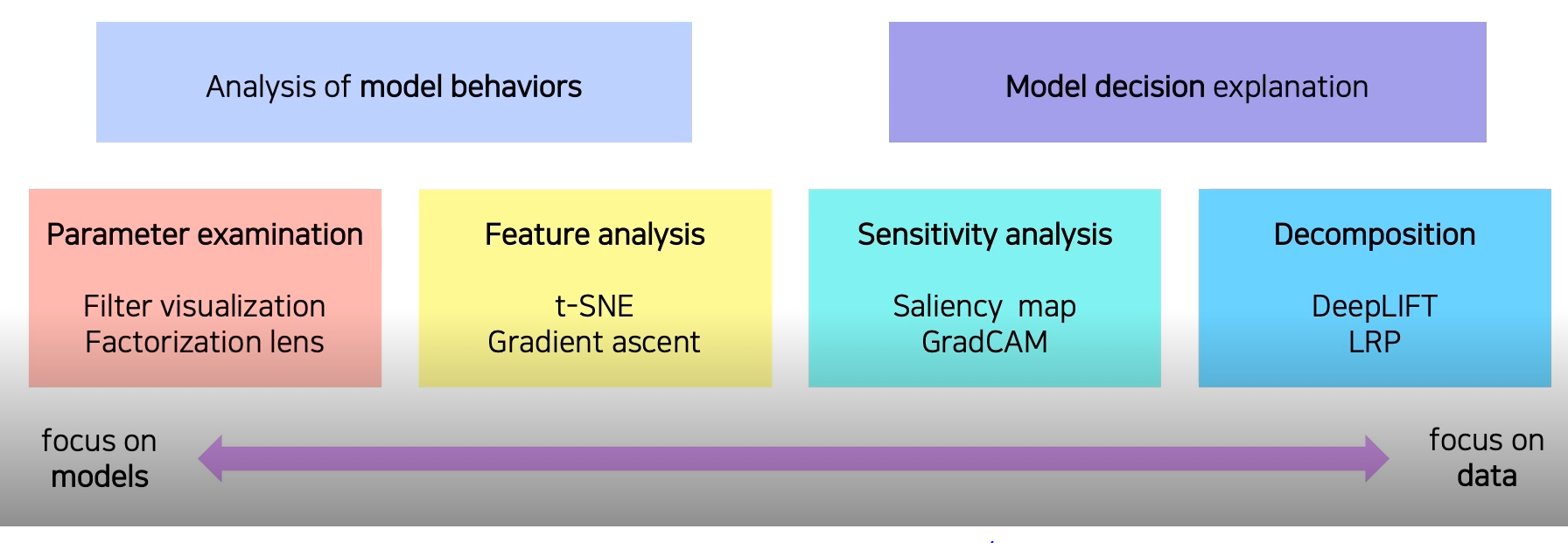
- CNN을 visualizing하는것을 통해 내부의 동작을 확인할 수 있고 이로 인해 디버깅을 할 수 있다.
ECCV 2014
- deconvolution을 사용해 각 Layer마다의 출력을 확인
- CNN Layer에 따라 Low Level, Middle Level, High Level에서 각각 어떤 특징을 학습하는지 확인하며 model을 튜닝 할 수 있다.