Data augmentation
- 대부분 사진들은 사람이 찍은것 이기 때문에 bias되어있다.
- 실제 모델이 학습하는것은 현실세계의 데이터의 분포중 smaple이다. 학습된 데이터에서 찾을 수 없는 데이터가 입력으로 들어온 경우 모델은 제대로된 답을 제시할 수 없다.
- 이를 해결하기 위해 학습을 시킬 때 augmentation한 데이터를 학습시킨다.
- Crop, Shear, Brightness, Perspective, Rotate 등..
- Brightness adjustment
- 밝기의 경우 일정 숫자를 더해주면 된다.
1 2 3 4 5 6 7 8 9 10
def brightness_augmentation(img): img[:,:,0] = img[:,:,0] + 100 img[:,:,1] = img[:,:,1] + 100 img[:,:,2] = img[:,:,2] + 100 img[:,:,0][img[:,:,0]>255] = 255 img[:,:,1][img[:,:,1]>255] = 255 img[:,:,2][img[:,:,2]>255] = 255 return img
- rotate, flip
- numpy와 cv의 함수를 사용하면 된다.
1 2
img_ratated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE) img_FLIPPED = cv2.rotate(image, cv2.ROTATE_180)
- Crop
- 중요한 부분을 더 강하게 학습 시킬 수 있는 기법
- Cropping image using numpy
1 2 3 4 5
y_start = 500 crop_y_size = 400 x_start = 300 crop_x_size = 800 img_cropped = image[y_start : y_start + crop_y_size, x_start : x_start + crop_x_size, :]
- Affine transformation
- 변환 전 후에 선은 선으로 길이의 비율은 일정하게 유지가 되고, 평행관계가 유지된다.
![Eff1]()
- Affine transformation using opencv
1 2 3 4 5
rows, cols, ch = image.shape pts1 = np.float32 ([[50, 50],[200,50],[50,200]]) pts2 = np.float32([[10,100],[200,50],[100,250]]) M = cv2.getAffineTransform(pts1, pts2) shear_img = cv2.warpAffine(image, M, (cols, rows))
매핑하고 싶은 좌표의 대응쌍을 getAffineTransform에 넣어주면 변환 행렬이 나오고 warpAffine을 호출하면 변환이 된다.(warpAffine가 영상의 픽셀 위치를 옮겨준다.)
- Cut mix
- 영상의 일부를 잘라 다른 영상에 합성하는것
- 단순히 영상만 합성하는것이 아닌 label 같은 비율로 합쳐준다.
- 단순한 작업으로 유의미한 수준의 성능 향상과 물체의 위치를 더 정교하게 찾아낼 수 있게 학습이 된다.
- 영상의 일부를 잘라 다른 영상에 합성하는것
- RandAugment
- 랜덤하게 augmentation기법을 사용해 학습하고 성능이 잘나오는 것을 사용한다.
- 가장 좋은 augmentation Policy를 찾는다.
- Sample a policy : Policy = {N augmentations to apply} by random sampling
- 거의 대부분의 경우에서 성능이 향상된다.

Leveraging pre trained information
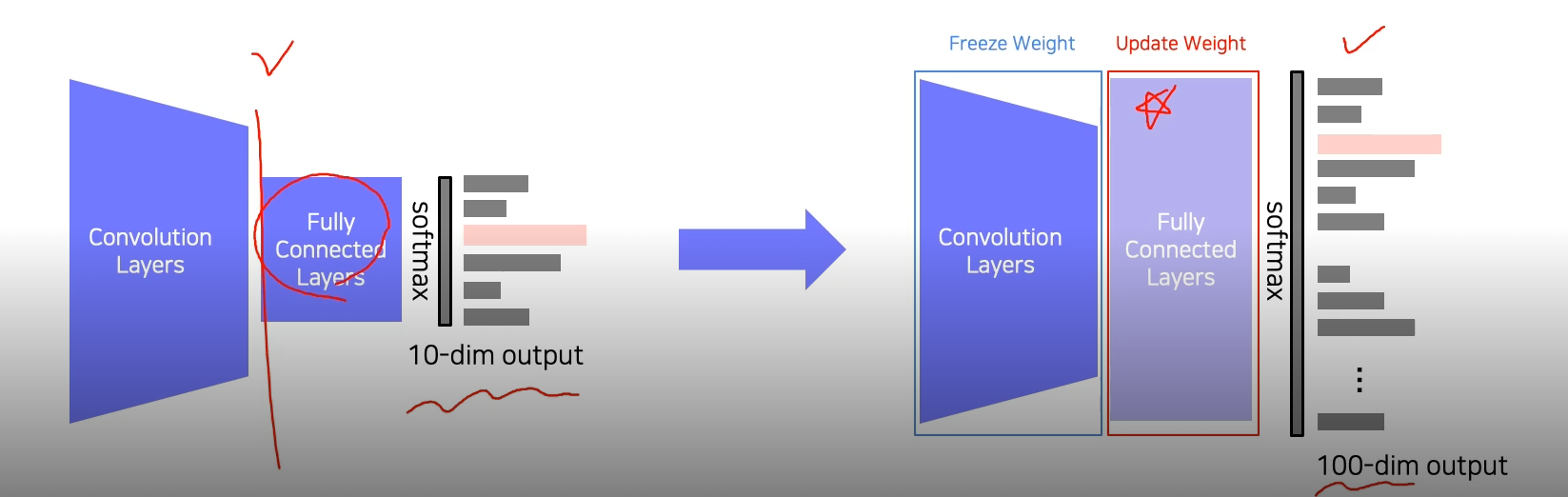
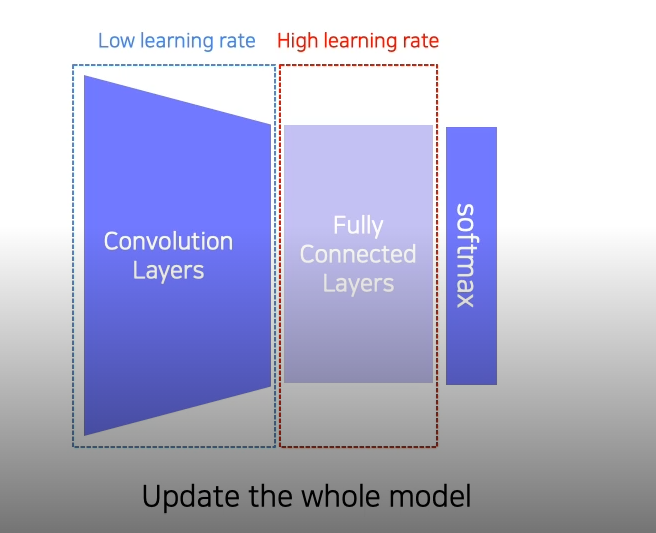
- Transfer learning을 사용하면 기존에 학습시켜놓은 사전 지식을 활용해 연관된 새로운 테스크에 적은 노력으로 높은 성능에 도달이 가능하다.
- Transfer learning은 한 데이터 셋에서 다른 데이터셋을 활용하는 기술
Knowledge distillation
- 이미 학습된 teacher network의 지식을 작은 모델은 student model에 주입해서 사용
- 큰 모델에서 작은 모델로 지식을 전달함으로써 모델압축에 유용하게 사용하는 방법
- 최근에는 Teacher에서 생성된 출력을 unlabeled된 pseudo label로 자동생성하는 방법을 사용한다.
- 일반적인 방법 - > label을 전혀 사용하지 않음
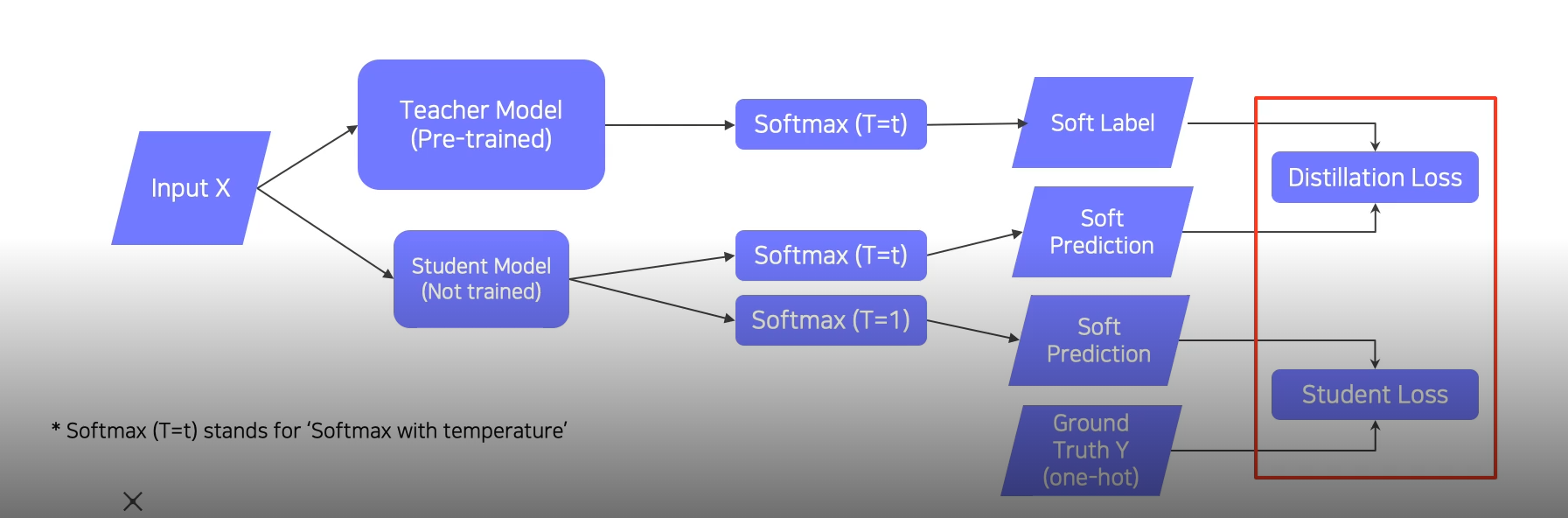
- pre trained 모델을 teacher model로 준비하고, train되지 않은 student model을 초기화 한다.
- 같은 입력에 대해서 teacher의 output, student의 output을 KL div. Loss를 사용해 backpro해서 student만 학습한다.
Label이 존재할 경우
![Eff4]()
- 일반적인 영상을 학습할 때 정답 레이블은 n개의 클래스 중 하나라는 표시를 위해 one-hot vector를 사용한다. → hard label
- soft label은 각 class를 나타내는 숫자가 확률로 표시된다 (softmax)
- knowledge distillation에서 softmax를 취해 soft label을 사용한다.
- 단순히 softmax만 취하면 입력의 값을 극단적으로 벌리게된다(극단적으로 차이가 벌어진다.). 이때 temperature T로 입력값을 나누어서 softmax를 취하게되면 출력을 좀더 스무스하게 나오게 해준다.
- Semantic information은 사용하지 않는데 teacher의 output이 pre train에서 사용되었던 이전 task클래스들과 연관이 되어있기 때문에 student가 학습하려는 data와 다른 dataset이므로
- Distillation Loss
- KLdiv(Soft label, Soft prediction)
- Student Loss
- CrossEntropy(Hard label, Soft prediction)
- student의 출력이 true label과 일치하도록 만드는 loss
Semi supervised learning
- unlabel된 엄청 큰 데이터와 적은 수의 label된 데이터를 둘 다 활용하는 방법
- 학습 방법
- label data로 pre train한다.
- unlabel data의 pseudo label을 pre train한 모델로 생성한다.
- 생성된 pseudo label과 label 된 data를 모두 활용해 새로운 모델을 학습시킨다. (혹은 이전 모델을 재학습)
Self training
- Augmentation + Teacher-Student networks + semi Supervised learning
- 학습 방법
- ImageNet dataset을 이용해 Teacher network를 학습시킨다. (labeled된 1M 사용)
- pseudo label을 Teacher로 생성한다. (labeled되지 않은 300M에 대해서 생성)
- 두 데이터를 합쳐 student model을 randAugment를 사용해 더 방대한 양의 데이터로 Student를 학습시킨다.
- Student모델 학습이 끝나면 현재 Student Network를 새로운 Teacher network로 하여 위의 과정을 반복한다.
- Student model을 조금씩 더 커지게 한다.