self Supervised pre-Training model
- Transformer의 Self-Attention block은 범용적인 Decoder, Encoder로써 NLP뿐만 아니라 다양한 곳에 활용되고 있다.
- 기존 Transformer는 6개의 block을 stack해서 encoder, decoder로 사용했지만 이후 나오는것들은 더 많은 block을 사용해 대규모 학습 데이터를 사용해 self-supervised learning framework로 학습한 뒤 다양한 Task의 Transfer learning형태로 Fine tuning해서 사용한다.
- 하지만 Transformer구조를 사용하는 생성 모델의 경우 Decoder가 순차적으로 결과를 생성하기 때문에 여전히 Greedy decoding에서 벗어나지 못한다.
GPT-1

- 순차적으로 다음 단어를 예측하는 Language modeling Task를 통해 학습된다.
- GPT-1은 다수의 문장이 존재하는 경우에도 큰 모델의 변경없이 사용할 수 있다.
- 긍정부정 예측 : Extract토큰(특별한 EOS토큰)을 붙혀 Encoding한 뒤 최종적으로 나온 Extract에 해당하는 Encoding vector를 output Layer를 통과한 결과로 Task를 수행한다.
- Entailment : 전제가 있을때 가설이 참인지 알아내는 Task로 전제와 가설사이에 Delim Token을 추가해 하나의 Sentence로 만들어 Encoding을 수행한다. 분류와 마찬가지로 Extract에 해당하는 Encoding vector를 output Layer를 통과한 결과로 논리적으로 내포 관계인지 모순 관계인지 확인한다.
- 만약 특정 글들이 어떤 class에 속하는지를 학습하려 할 경우 GPT의 output Layer를 사용하지 않고 출력된 embedding vector를 사용해 이것을 분류를 위한 Layer를 만들어 학습시키는 것으로 Fine Tuning할 수 있다.
GPT의 경우 다음 단어를 예측해야하기 때문에 특정 time step에서 다음 단어의 정보를 사용하면 안된다(transformer 에서의 decoder에서 mask해서 처리한것처럼).
→masked selfattention 사용
BERT
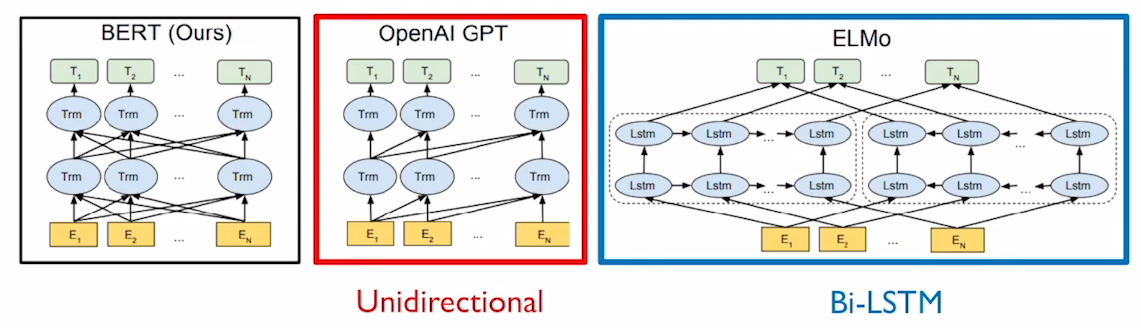
- GPT-1의 경우 전후 문맥을 보지않고 앞의 단어만 보고 단어를 예측하는 방식으로 학습을 시켰는데 BERT는 양쪽의 정보를 모두 고려하여 학습한다. (Transformer에서 encoder에서 사용하는 self attention을 사용)
- BERT는 특정 확률로(hyper parameter) 단어를 MASK하여 MASK된 단어를 예측하도록 학습된다. 이러한 학습으로 인해 모델이 MASK가 포함되어 있는 처리한 모델로 학습이 될것이다. BERT에서는 15%를 제시
- 15%의 단어를 전부 MASK한다면 여러 부작용이 생길 수 있다. pre train 당시에는 주어진 문장에서 평균적으로 15%의 단어가 MASK되어 있는 상황에 익숙해진 모델이 나올 것이다.
- 이런식의 모델이 나오면 분류같은 down stream task를 위해 fine tuning하면 input에 더이상 MASK가 없기 때문에 입력의 양상이 달라 원하는 결과를 얻지 못할 수 있다.
- 해결
- 15%의 MASK로 치환될 단어들 중 80%를 MASK Token으로 변경한다.
- 15%의 MASK로 치환될 단어들 중 10%은 random word로 치환한다.
- 문법에 맞지 않는 단어도 원래의 단어로 잘 복원할 수 있도록 문제의 난이도를 높힘
- 15%의 MASK로 치환될 단어들 중 10%은 변경하지 않는다.
- 결과에서 해당단어는 변경되지 않고 나올 수 있도록 문제의 난이도를 높힘
- WordPiece embedding
- 좀더 세밀한 단위로 단어를 구별한다 (pre-training의 경우 pre, training 같이)
- Segmentation embedding
문장 레벨에서의 position을 반영한 벡터
![Transformer3]()
He의 경우 전체 위치를 볼 경우 6번째 위치이지만 문장별로 본다면 2번째 문장의 첫번째 단어가 된다. 이를 고려해기 위해 segment embedding vector를 추가로 사용한다.

Fine-tuning

- 내포, 모순관계를 알기위한 모델의 경우 두개의 문장을 [SEP]를 사용해 하나의 input으로 사용하고 [CLS]에 해당하는 encoding vector를 output layer로 주어 Task를 수행한다.
- 단인 문장 분류 문제의 경우도 [CLS]에 해당하는 encoding vector를 output layer로 주어 Task를 수행한다.
BERT vs GPT-1
- training-data size
- GPT는 800M word, BERT는 2500M word를 사용해 학습
- Batch size
- 일반적으로 큰 size의 batch 를 사용하면 최종 모델성능이 더 좋아지고 학습도 안정화가 된다. → Gradient descent를 수행할 때 더 많은 데이터를 고려해 업데이트하기 떄문
- BERT : 128000words
- GPT : 32000words
- Task-specific fine-tuning
- GPT의 경우 5e-5라는 동일한 lr을 사용
- BERT는 Task별로 다른 lr을 사용
Machine Reading Comprehension (MRC)
- BERT를 fine tuning해서 좋은 결과를 얻을 수 있는데 대표적인 TASK
- Document를 해석하고 Question에 대답해주는 Task이다.
- 이러한 Task를 위한 Dataset으로 SQuAD가 있다.
GPT-2
- Motivation
- Multitask learning as Question Answering
- 해당 논문에서는 다양한 자연어 처리Task가 질의응답으로 바꾸어 통합된 자연어 생성으로 다양한 Task를 처리할 수 있다고 말하였다.
- 예를들어 문장이 긍정, 부정인지 분류하고자하면 “해당 문장이 긍정이냐 부정이냐” 라는 answer을 한것이다.
- 요약 Task의 경우 “주어진 문장의 요약이 무엇이냐” 라는 answer을 한것이다.
- Multitask learning as Question Answering
- Dataset
- 높은 수준의 글을 선별적으로 사용(Reddit..)
- Preprocess
- Byte pair encoding
- Modification
Layer가 위로 올라감에 따라 index에 따라 init값을 더 작게 하였다.
→ Layer가 위로 갈 수록 선형변환의 값이 0에 가까워지도록
→위쪽의 Layer가 하는일이 더 줄어들도록
- 번역, 요약등을 zero shot setting으로 잘 동작할 수 있다는 가능성을 보여주었음
GPT-3
- GPT-2에 비해서 구조적 변화가 아닌 더 많은 Layer, 더 많은 학습데이터를 사용
- GPT-2로 보여주었던 Zero shot setting에서의 가능성을 놀라운 수준으로 올렸다.

- 별도의 fine tuning 없이 번역 등의 Task가 잘 수행된다.
- 모델이 커질수록 더 좋은 성능이 나온다는 통계를 보여주었음
ALBERT
- 기존 BERT가 가지던 성능의 하락없이 모델 size와 학습 시간이 빨라지는것을 목표로 모델제시
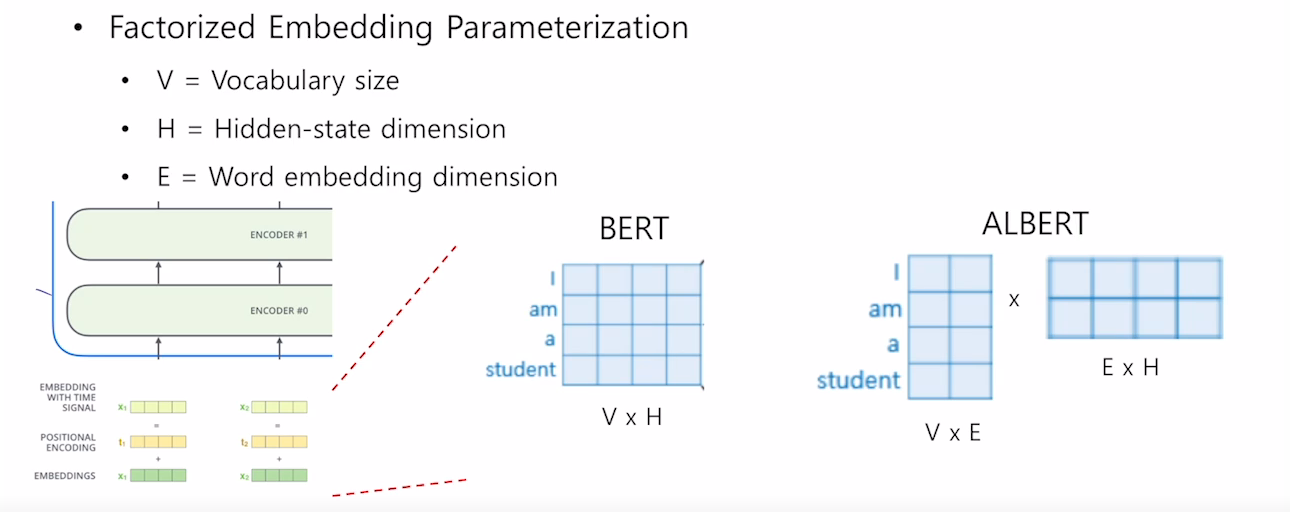
- Cross-Layer Parameter sharing
- Sentence order Prediction
ELECTRA
- Language model을 통해 단어를 복원해주는 generator라는 모델을 두고, 주어진 Masked Language를 generator를 통해 Masked된 단어를 예측하고 Discriminator(ELECTRA)모델을 사용해 각각의 단어가 원래의 단어인지 replace된것인지 확인하는것으로 학습한다.
- 학습된 Discriminator를 pre-training model로 사용한다.