- RNN처럼 sequence를 처리하지만 하나에 하나의 토큰을 처리하는것이 아닌 한번에 처리한다.
- attention을 사용하는 방법론 이면서 학습과 병렬화를 쉽게해 속도를 높혔다.
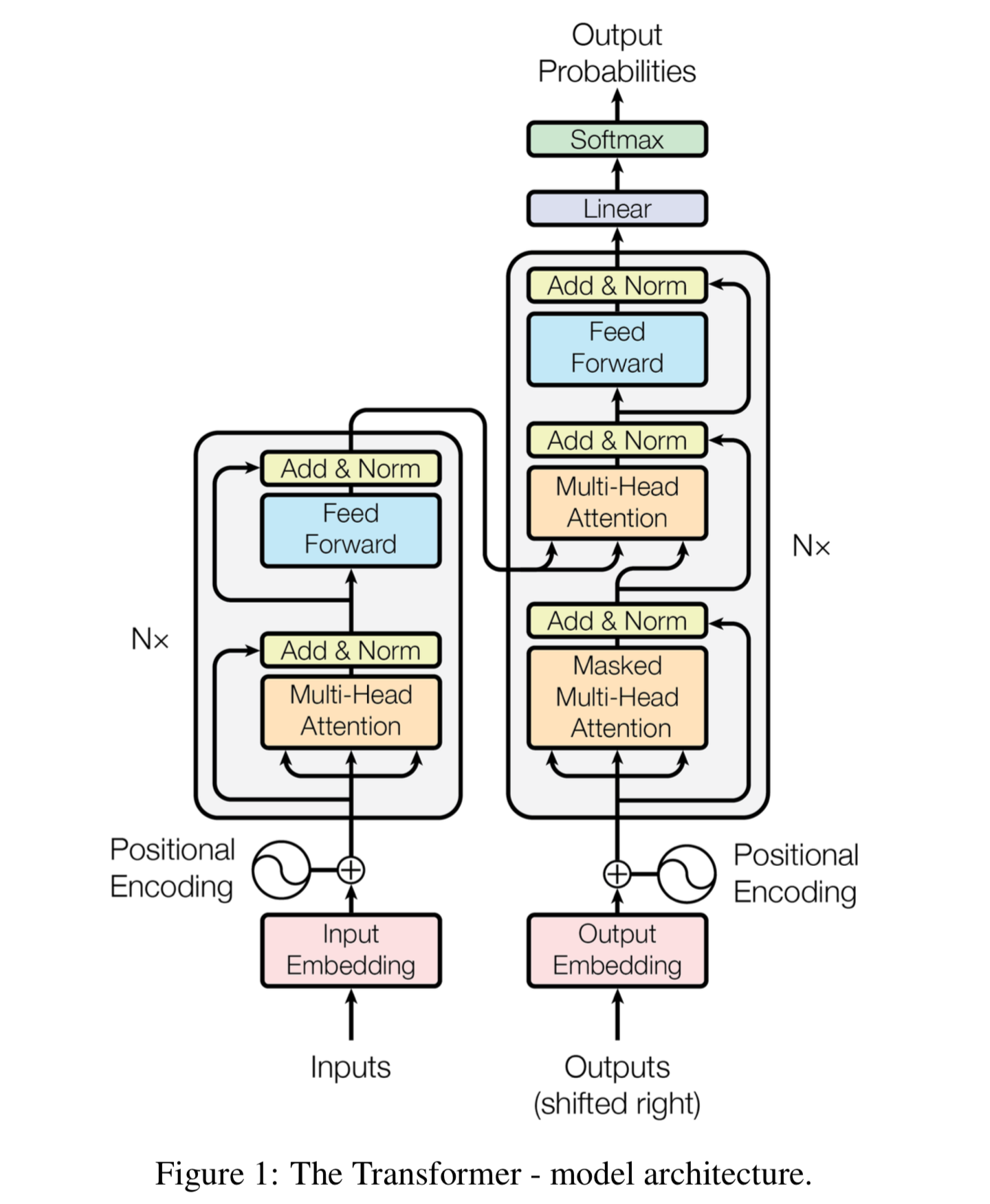
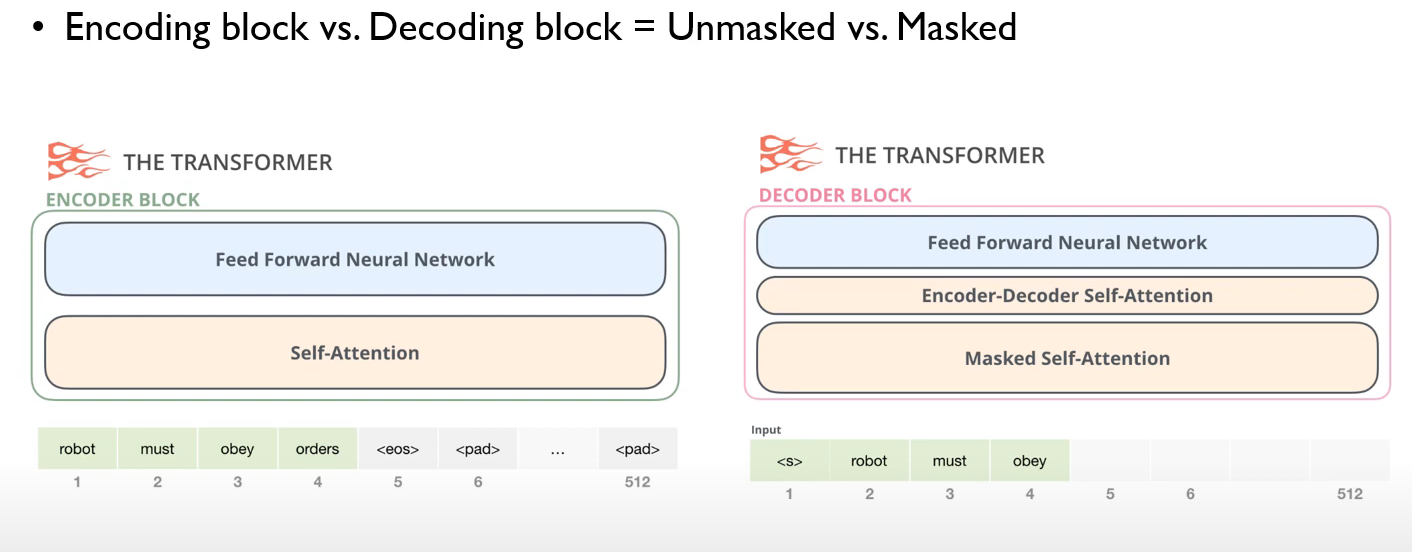
Encoder, Decoder
- encoding component (stack of encoders)
- Unmasked : 인코딩 과정에서는 문장 전체가 한번에 Self-Attention, Feed Forward NN을 통과한다.
- Encoder는 Self attention layer와 Feed Forward Neural Network의 두개의 sub layer로 구성되어 있다.
- 각각의 Encoder block는 같은 구조를 가지고 있지만 가중치는 공유하지 않는다.
- self attention : 하나의 토큰을 처리할 때 input으로 주어진 다른 토큰들을 얼마나 중요하게 볼것인지를 계산하는 Layer이다. (token 별 dependency존재)
- Feed Forward Neural Network : self attention의 출력 각각의 토큰별로 NN을 적용하는 Layer이다. (toekn 별 dependency 존재 없음)
- decoding component (stack of decoders)
- masked : 디코딩 과정에서는 앞에서 부터 순차적으로 생성해야 하기 때문에 뒤의 단어는 마스킹 한다.
- 예를들어 4번째 단어를 디코딩할 때 4번째 이후의 단어는 마스킹 처리를 한다.
- Decoder는 3개의 sub Layer로 구성되어 있다.
- Encoder-Decoder Attention : 최종적인 output을 산출할 때 Encoder에서 주어진 정보를 어떻게 반영할지를 결정하는 Layer
input embedding
- input 단어들을 embedding algorithm을 사용해 word embedding한다.
- 512차원의 word embedding를 사용한다.
- 첫번째 input block에만 input embedding된 word가 들어가게 되고, 이후 stack의 block으로는 이전 block의 output을 받게된다.
positional Encoding
- transformer는 한번에 모든 input sequence를 처리하기 때문에 각 단어의 위치 정보를 고려할 수 없다. 그래서 positional Encoding을 사용한다.
- positional Encoding은 input sequence의 위치 정보를 반영해주기 위해 사용한다.
- positional Encoding은 input embedding에 더해지는 벡터이다.
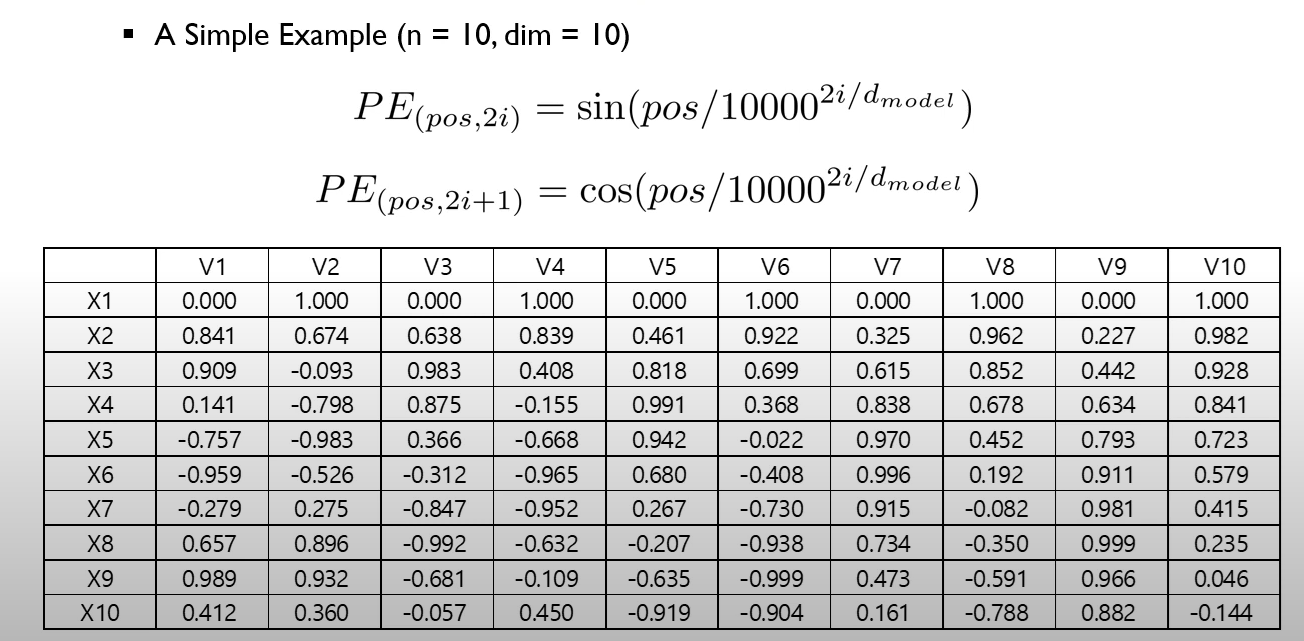
- 위의 식을 토대로 각 positional encoding vector의 거리를 계산하면 아래와 같은 결과가 나온다.
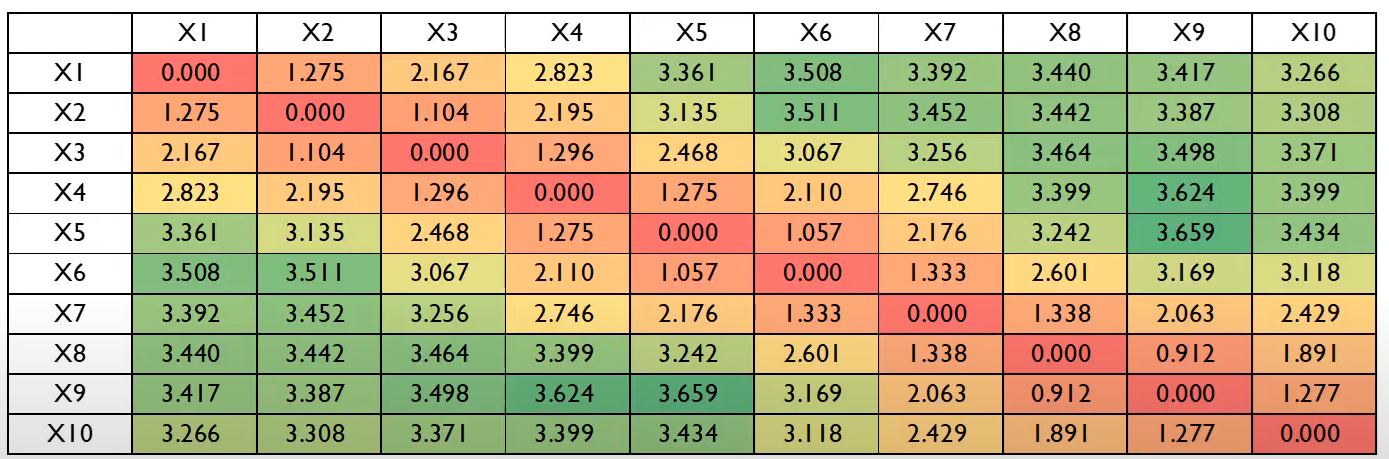
- n, n의 경우 자기 자신과의 거리이므로 0인것을 확인할 수 있고 대각으로 갈 수록 값이 커지는것을 볼 수있다. 이러한 결과가 위와 같은 식을 사용하는 하나의 이유이다.
Self-Attention
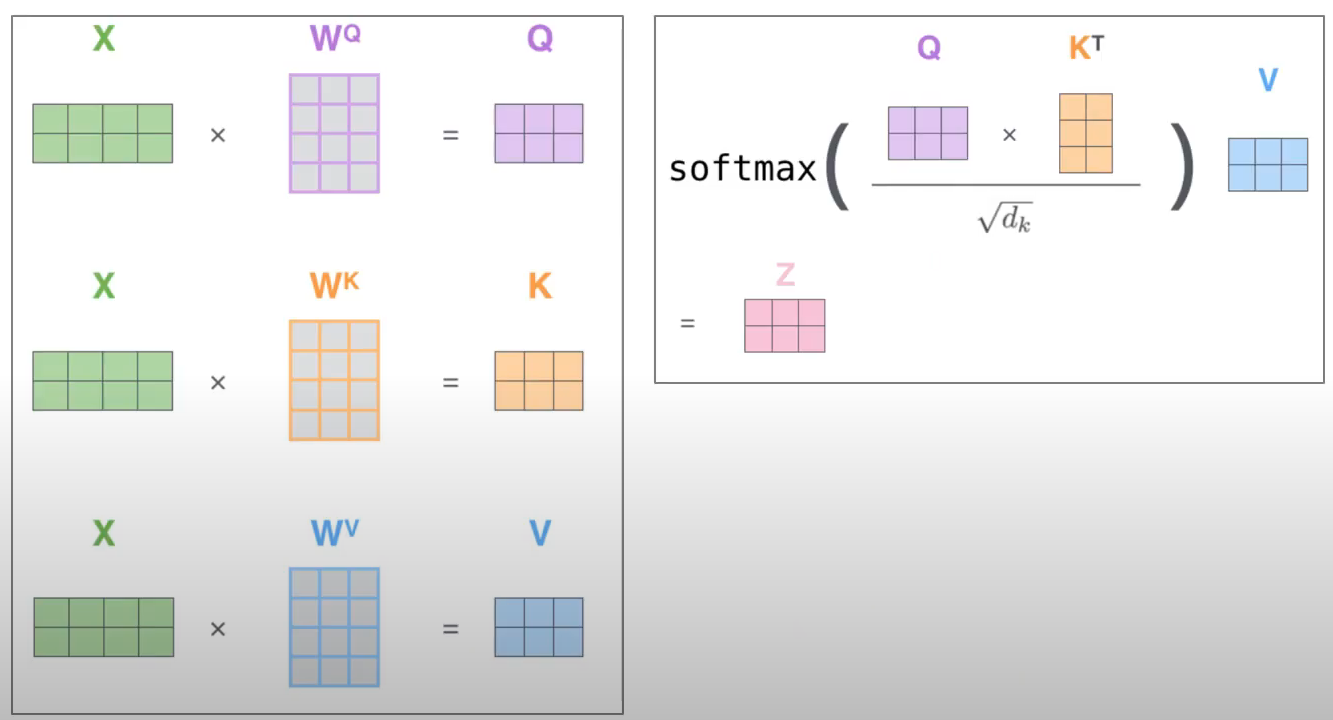
- 각각의 input vector로부터 3종류의 vector를 만든다.
- Query : 현재 보고 있는 단어의 값, 다른 단어를 scoring하기 위해 기준이 되는 값
- Key : label과 같은 역할, Query가 주어졌을 때 관련된 값을 찾을 때 사용한다.
- Value : 다른 단어와의 관계까지 고려해서(Query와 Key를 사용해) 계산한 값
- 각 벡터를 계산하기위한 행렬들은 학습을 통해 update된다.
- 절차
- input vector로 부터 Query, Key, Value벡터를 계산한다.
- input/output vector의 차원이 512일때 보통 Q, K ,V 는 64차원을 사용한다.
- 무조건 작을 필요는 없지만multi-headed attention관점에서 concatenate를 수행하려면 작아야 좋다.
- 각 토큰 별로 다른 토큰들과의 score를 계산한다.
- 각 단어별 Query와 다른 단어의 Key를 곱해서 계산
- score값을 $\sqrt{d_k}$로 나누어준다.
- 이 과정은 좀더 stable한 gradient가 나오게해준다.
- 계산한 결과에 softmax를 취해 나온 결과
- softmax를 취해 나온 확률 값은 현재 단어가 해당 단어와 얼마나 관계가 있는지를 나타낸다.
- 각각의 계산결과를 각각의 value벡터를 곱하고, 이 모든 결과를 덧셈을 통해 현재 단어의 최종 output을 만든다.
![Transformer4]()
![Transformer5]()
- input vector로 부터 Query, Key, Value벡터를 계산한다.

multi-headed attention
- 위에서 설명한 방식은 하나의 attention을 사용하는 방법이다. 실제로는 여러개의 attention을 사용하는 multi-headed attention을 사용한다.
- 하나의 z값만 뽑는것이 아닌 하나의 단어별로 여러개의 z를 출력하는방법이다.
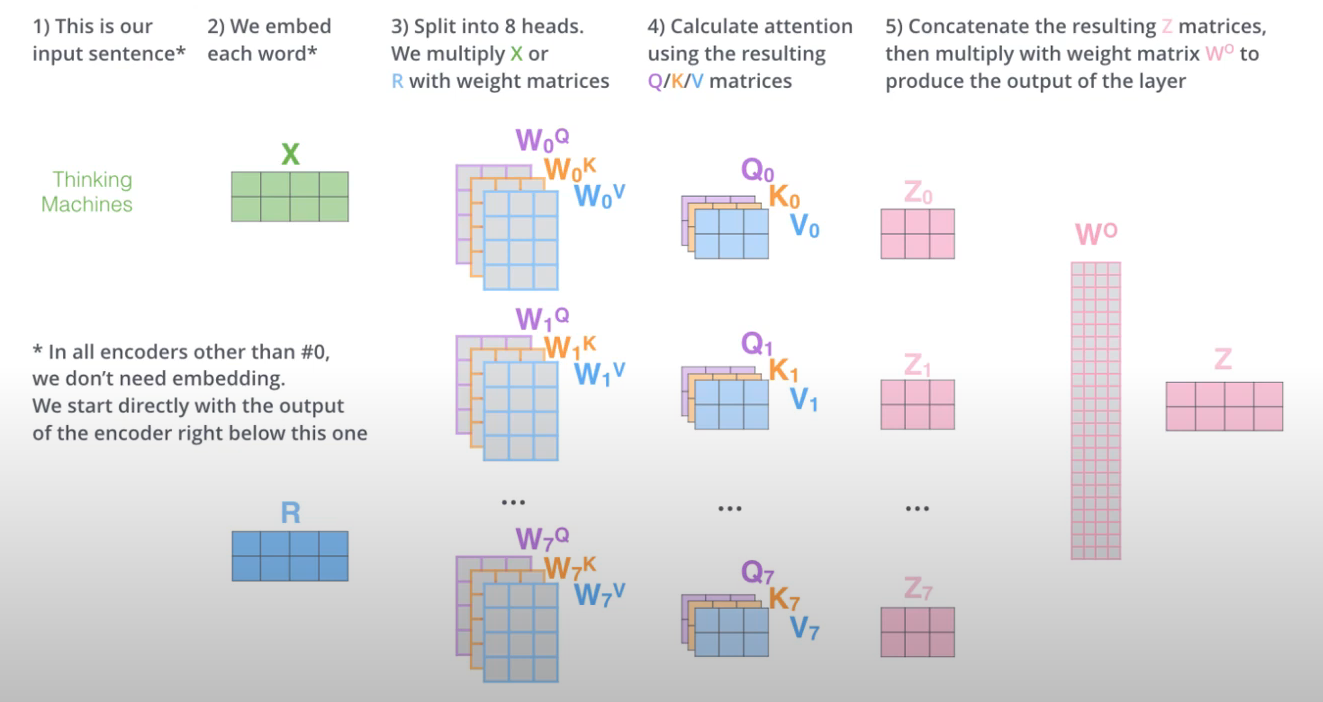
- 각 black당 같은 구조(같은 input크기가 필요)이므로 attention별 출력을 concatenate하고 가중치 행렬과 행렬곱을 통해 처음 input과 똑같은 크기로 만들어준다.
Residual & Layer Normalize
- Residual은 어떤 입력의 output에 자기 자신을 더해주는것 (ResNet에서 나온것)
- 이러한 Residual은 f(x) + x와 같은 형태로 만들어 미분을 하게되었을 때 f(x)의 미분이 매우 작아도 더해진 x로 인해 최소한 1의 gradient를 가지게 해주어 학습에 유리하다.
- Self Attention의 결과에 인풋값을 더해주고(Residual) Normalize를 해주는데 Transformers에서는 LayerNormalize를 사용한다.
- 이후 Feed Foward block을 거쳐 다시 Residual과 Normalize를 해주고, 다음 Encoder block으로 넘어간다.
Position-wise Feed-Forward Networks
- 각각의 토큰 별로 적용되는 fully connected layer이다.
- $FFN(x) = max(0, xW_1+b_1)W_2+b_2$
- FFN은 각 토큰별로 독립적으로 계산되지만 같은 Encoder block의 FFN의 파라미터는 모두 같다.
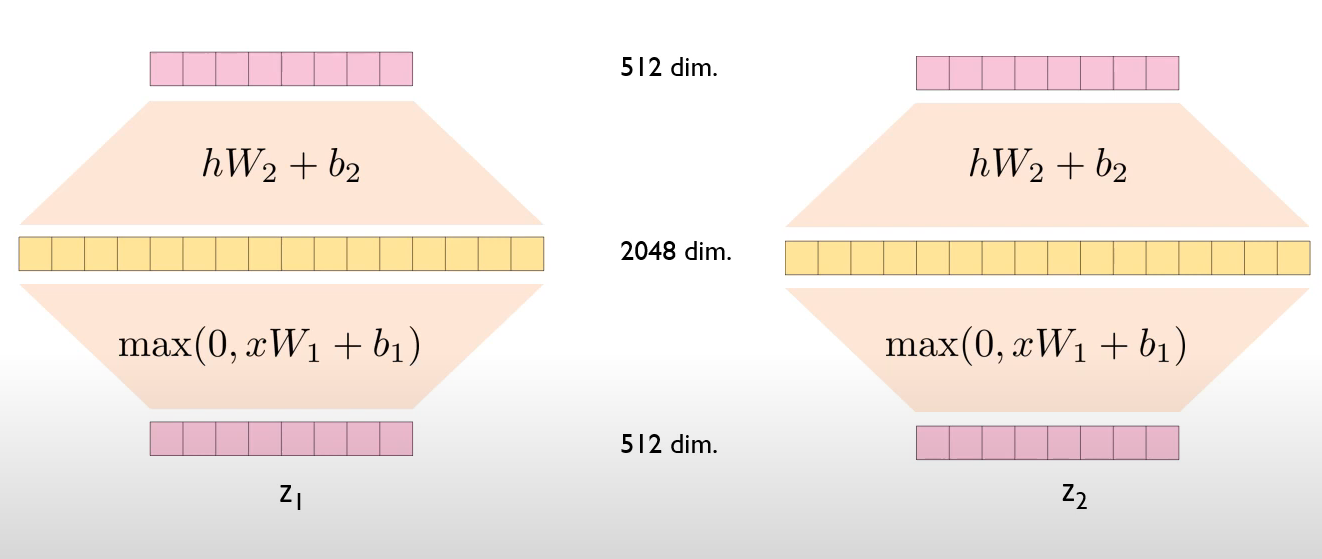
- 각 z가 같은 가중치 행렬을 사용하기 때문에 kernel size가 1인 Conv 연산이라고 생각하면 편하다.
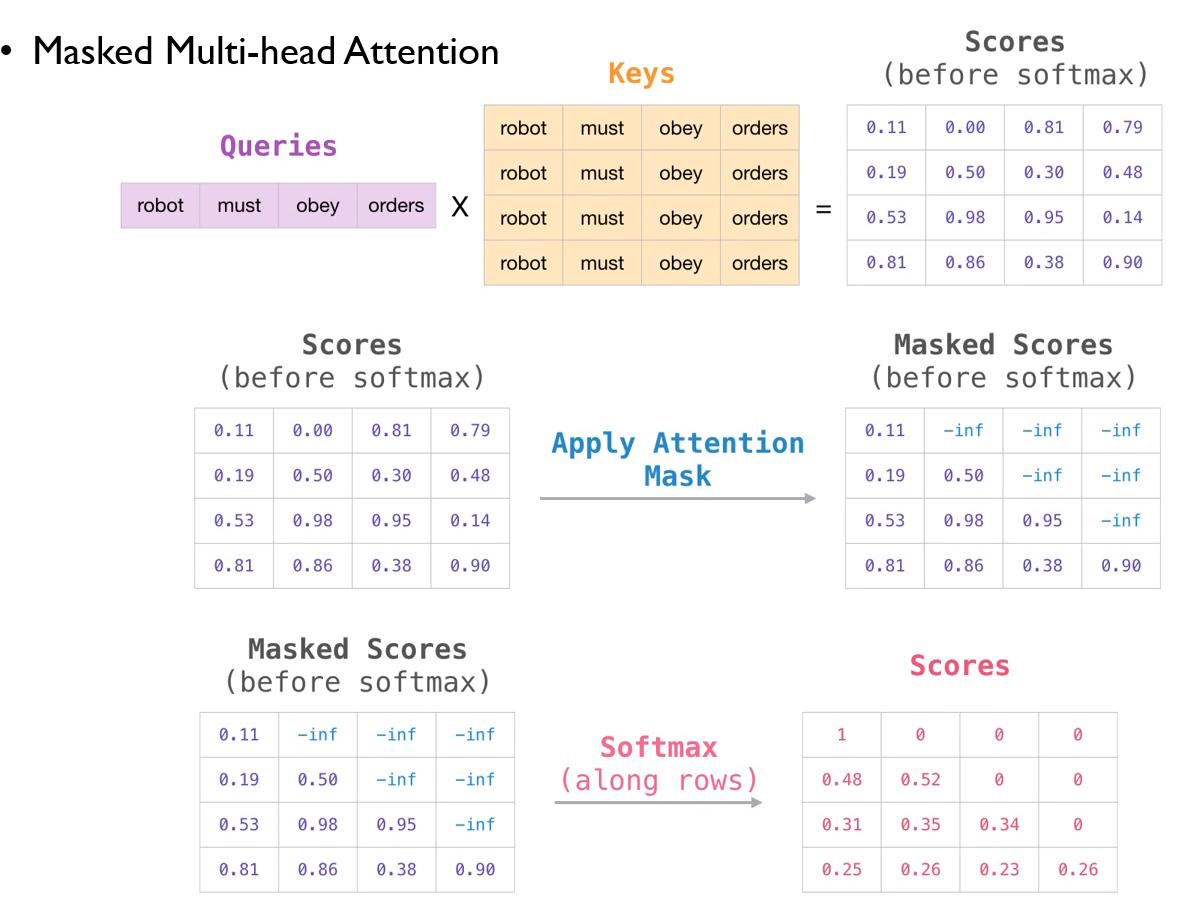
Masked Multi-head Attention
- Decoder의 Self Attention Layer는 반드시 자기보다 앞쪽에 있는 토큰들의 attention score만 볼 수 있어야한다.
- 현재 해당하는 토큰보다 뒷쪽의 score값은 -inf로 설정해서 계산한다.
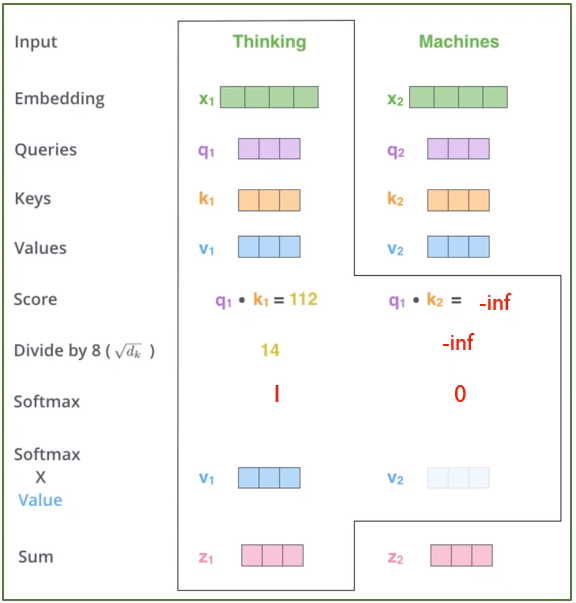
- 똑같이 계산하고 masking처리를 해주면 된다.