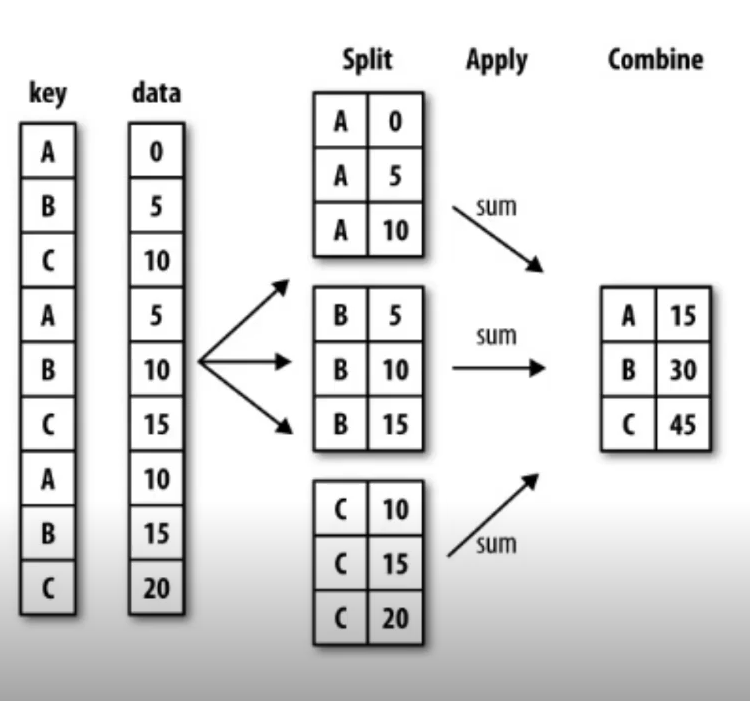
Groupby
SQL의 groupby 명령어와 같다. split→apply→combine과정을 거쳐 연산된다. pandas의 groupby는
df.groupby[기준 column][적용받는 컬럼].적용할 연산의 형태로 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
raw_data = {
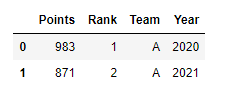
"Points": [983,871,666,554,234],
"Rank": [1,2,2,3,3],
"Team": ["A","A","B","B","C"],
"Year": [2020, 2021, 2019, 2018, 2019]
}
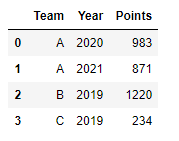
df = pd.DataFrame(raw_data, columns=["Points", "Rank", "Team","Year"])
df.groupby("Team")["Points"].sum()
# Team
# A 1854
# B 1220
# C 234
# Name: Points, dtype: int64
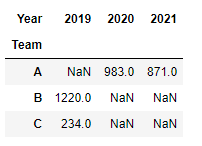
df.groupby(["Team","Year"])["Points"].sum()
# Team Year
# A 2020 983
# 2021 871
# B 2019 1220
# C 2019 234
# Name: Points, dtype: int64
group할 column을 list로 묶어서 전달할 수 있다. group은 앞에것부터 우선적용 되어 묶여진다.
이렇게 list로 묶어서 column을 지정하면 index가 “Team”, “Year” 두가지로 나오는데 이렇게 index가 여러개인 구조를 Hierarchical index라고한다.
1
2
3
4
5
6
7
g_df = df.groupby(["Team","Year"])["Points"].sum()
g_df.index
# MultiIndex([('A', 2020),
# ('A', 2021),
# ('B', 2019),
# ('C', 2019)],
# names=['Team', 'Year'])
Hierarchical index
groupby의 리턴값은 Series이다. 따라서 series의 함수들을 다 사용할 수 있는데 Hierarchical index의 경우 index level을 지정해줘야한다.
1
2
3
g_df.sum(level=1)
g_df.std(level=1)
...
unstack
1
g_df.unstack()
unstack을 사용하면 matrix형태로 풀어준다. unstack()한것을 stack()하면 원상태로 복구
![pandas2]()
reset_index
1
g_df.reset_index()
reset_index를 사용하여 변경할 수 있다.
![pandas3]()
swaplevel
index의 위치를 swap한다.
g_df.swaplevelsort_index(level=0)
parameter로 전달한 level의 index를 기준으로 정렬한다.
g_df.sort_index(level=1)sort_values()
data기준으로 정렬한다.
g_df.sort_values()
Grouped
Split된 상태를 추출이 가능하고 이런 상태를 Grouped상태라고 한다. groupby에 column만 작성하면 grouped상태를 얻을 수 있다. grouped 상태는 key value형태로 값을 추출할 수 있다. grouped는 generator형태이기 때문에 list로 출력하거나 for문으로 사용해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
grouped = df.groupby("Team")
for name,group in grouped:
print (name)
print (group)
# A
# Points Rank Team Year
# 0 983 1 A 2020
# 1 871 2 A 2021
# B
# Points Rank Team Year
# 2 666 2 B 2019
# 3 554 3 B 2019
# C
# Points Rank Team Year
# 4 234 3 C 2019
grouped상태에서 특정 그룹만 얻고 싶다면 get_group를 사용하면 된다.
1
grouped.get_group("A")
grouped상태에서는 세 가지 유형의 apply가 가능하다.
Aggregation
요약된 통계정보를 추출할 수 있다. max, sum, mean등등
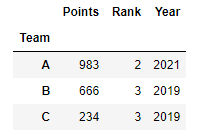
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# A # Points Rank Team Year # 0 983 1 A 2020 # 1 871 2 A 2021 # B # Points Rank Team Year # 2 666 2 B 2019 # 3 554 3 B 2019 # C # Points Rank Team Year # 4 234 3 C 2019 grouped.agg(sum) grouped.agg(np.mean) grouped.agg(max)
각 group별, column기준으로 수행된다. max를 사용한 결과는 아래의 사진과 같다.
![pandas5]()
Team을 기준으로 Split된 결과이기 때문에 팀별로 각 Column의 max값을 추출해준 것이다.
Transformation
lambda 함수등을 사용해 데이터 변환한다. Group별로 연산을 수행해 각각의 data에 영향을 끼친다.
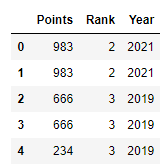
1 2
score = lambda x: (x.max()) grouped.transform(score)
![pandas6]()
group단위로 score함수가 apply되고, 그 결과를 각 data에 넣는것이다. max는 Series별로 연산이 되기 때문에 0,1번 index는 같은 그룹이기 때문에 같은값이 나온것을 볼 수 있다.
1 2
score = lambda x: x grouped.transform(score)
![pandas7]()
Filtration
특정 조건으로 정보를 검색할 수 있다.
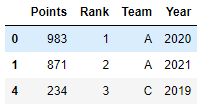
1
grouped.filter(lambda x: x["Rank"].sum() < 4)
![pandas8]()
위의 코드는 각 group의 rank의 합이 4미만인 데이터만 추출하는 코드이다.
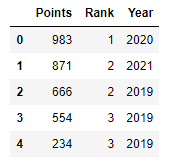
pandas 연습
1
2
3
4
5
6
7
8
9
10
11
12
13
import pandas as pd
import numpy as np
df = pd.read_csv("phone_data.csv")
df.dtypes
# index int64
# date object
# duration float64
# item object
# month object
# network object
# network_type object
# dtype: object
date의 타입을 dateutil을 사용해 날짜형태로 변경할 수 있다. dateutil.parser.parse는 문자형태를 날짜 타입으로 변경해준다.
1
2
3
import dateutil
df["date"] = df["date"].apply(dateutil.parser.parse, dayfirst=True)
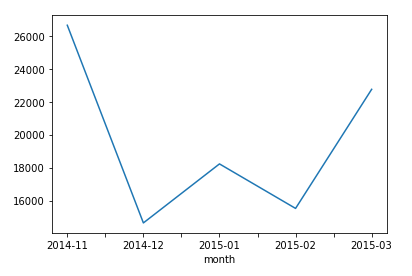
month별로 duration의 합계를 그래프로 볼 수 있다(matplotlib).
1
df.groupby("month")["duration"].sum().plot()
item이 call인 데이터만 확인할 수 있다.
1
df[df["item"] == "call"]
pivot Table
index축은 groupby와 동일하고, Column에 추가로 labeling값을 추가해 value에 numeric type값을 aggregation하는 형태이다.
1
2
3
4
5
6
7
df.pivot_table(values = ["duration"], # 실제 계산이 행될 value
index = [df.month, df.item], # 기준 index
columns = df.network, # 기준 column
aggfunc="sum", # aggregation할 함수
fill_value=0)
# df.groupby(["month","item", "network"])["duration"].sum().unstack()와 비슷한 결과
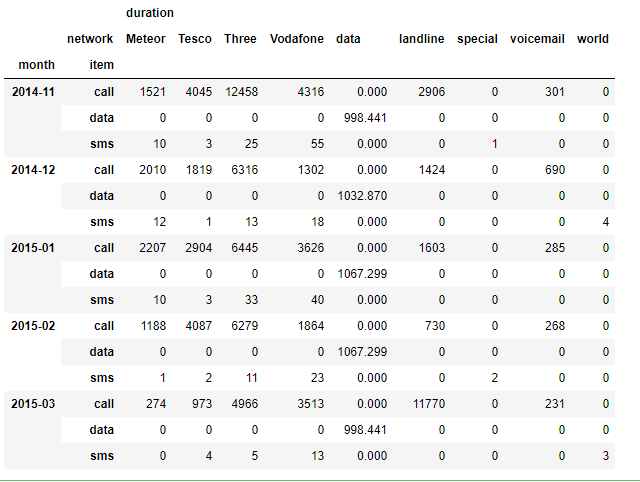
위의 코드는 month와 item을 index로 하여, network의 종류를 column으로 가지고 duration의 값을 sum한 pivot_table를 출력해준다.
Crosstab
pivot_table과 유사하다. 아래의 코드는 위의 pivot_table과 같은 결과를 출력한다.
1
2
3
4
pd.crosstab(index=[df.month, df.item],
columns=df.network,
values=df.duration,
aggfunc="sum").fillna(0)
merge
SQL의 Merge와 같은 기능으로 기준을 정해 두개의 데이터를 하나로 합친다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
raw_data1 = {
"subject_id": [1,2,3,4,5,6,7],
"test_score": [22,31,29,30,17,0,1],
}
raw_data2 = {
"subject_id": [4,5,6,7],
"name": ["kim","jung","park","lee"],
"class":["A", "B", "C", "D"]
}
df1 = DataFrame(data=raw_data1, columns=["subject_id", "test_score"])
df2 = DataFrame(data=raw_data2, columns=["subject_id", "name", "class"])
pd.merge(df1, df2, on="subject_id")
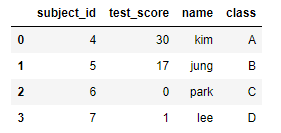
subject_id를 기준으로 두개의 DF를 merge한것이다. 두개의 column명이 다를 경우 아래와 같이 기준column을 각각 설정할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
raw_data1 = {
"subject_id": [1,2,3,4,5,6,7],
"test_score": [22,31,29,30,17,0,1],
}
raw_data2 = {
"id_subject": [4,5,6,7],
"name": ["kim","jung","park","lee"],
"class":["A", "B", "C", "D"]
}
df1 = DataFrame(data=raw_data1, columns=["subject_id", "test_score"])
df2 = DataFrame(data=raw_data2, columns=["id_subject", "name", "class"])
pd.merge(df1, df2, left_on="subject_id", right_on="id_subject")
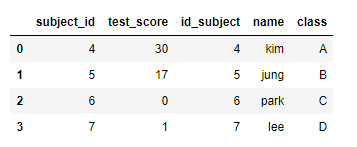
merge를 할 경우 몇가지 규칙이 있다.
how를 사용해 어떤 merge를 할지 선택할 수 있고, default는 inner join이다.
left join
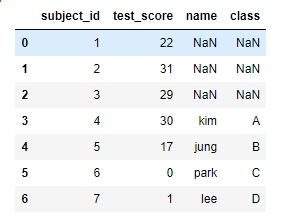
왼쪽을 기준으로 합치며 오른쪽에 있는 data라면 추가되지만 없는경우 NaN이된다.
1
pd.merge(df1, df2, on="subject_id", how="left")
![pandas16]()
right join
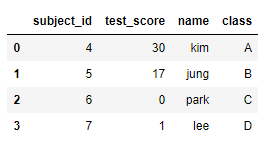
오른쪽을 기준으로 합친다.
1
pd.merge(df1, df2, on="subject_id", how="right")
![pandas17]()
오른쪽에 있는 subject_id는 왼쪽에도 모두 있으므로 NaN값이 들어간곳이 없음
full join
모든 데이터를 합친다.
1
pd.merge(df1, df2, on="subject_id", how="outer")
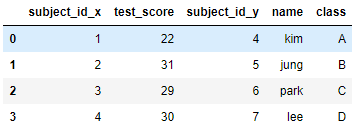
index based join
index를 기준으로 merge할 수 있다. 중첩되는 column은 x, y등을 붙혀서 구분해준다.
1
pd.merge(df1,df2,right_index=True, left_index=True)
![pandas18]()
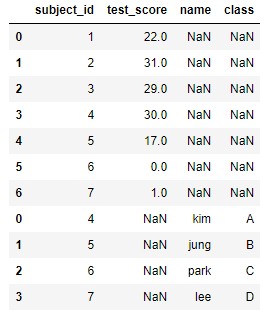
concat
concat은 merge와 다르게 table자체를 합쳐버린다. 기본은 열방향으로 붙히며 없는 데이터는 NaN이 채워진다. axis = 1로 해주면 옆으로 table을 합칠 수 있다.
1
pd.concat([df1,df2]) # df1.append(df2) 와 같은 결과
월별로 나누어진 파일 읽어오기
data디렉토리에 sales-[month]-2014.xlsx파일들이 있을 때 이 파일들을 한번에 읽어올 수 있다.
1
2
3
4
5
6
7
8
9
10
11
import os
# data 디렉토리에 2014.xlsx로 끝나는 파일 이름을 리스트로 받기
files = [file_name for file_name in os.listdir("./data") if file_name.endswith("2014.xlsx")]
# 각 파일을 읽어 DF list로 저장
# files리스트를 순회하며 각 파일명에 os.path.join을 사용해 Path를 만들어 read_excel로 읽기
df_list = [pd.read_excel(os.path.join("data",df_filename)) for df_filename in files]
# concat을 사용해 하나의 df로 합치기
df = pd.concat(df_list)
persistence
Database connection
Data loading시 db connection 기능을 제공한다.
1 2 3 4 5 6
import sqlite3 # 파일형태 db conn = sqlite3.connect("./data/flights.db") # flights db연결 cur = conn.cursor() cur.execute("select * from airlines limit 5;") # query를 사용해 특정 데이터를 가져올 수 있다. results = cur.fetchall() # 결과가 튜플형태로 들어옴
pandas의 read_sql_query를 사용해 DataFrame로 불러올 수 있다.
1
df_air = pd.read_sql_query("select * from airlines;", conn)
excel형태로 쓰기
XlsWriter를 설치해야한다.
1 2
writer = pd.ExcelWriter("저장위치/파일명.xlsx", engine ="xlsxwriter") df.to_excel(writer, sheet_name ="Sheet1")
pickle 읽고 쓰기
1 2
df = pd.read_pickle("pickle파일 경로") # 읽기 df.to_pickle("저장위치") # 쓰기