Pandas
Pandas는 구조화된 데이터의 처리를 지원하는 python의 라이브러리이다. numpy와 통합하여 강력한 “스프레드시트” 처리 기능을 제공한다(Tabular 데이터를 처리할 때 좋다).
데이터 읽어오기
1
2
3
4
5
import pandas as pd
data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data"
df_data = pd.read_csv(data_url, sep="\s+", header=None)
df_data.head()
위와같이 url을 작성해도 되고, 직접 파일의 경로를 작성하여도 된다. read_csv함수의 sep파라미터는 정규표현식을 작성한 것인데 현재 읽으려는 파일이 1개 이상의 공백으로 data가 구분되어 있기 때문에 위와같은 정규식을 사용하였다. header는 파일 내부에 column이 없기 때문에 None으로 작성하였고, 아래와 같이 숫자들이 자동으로 들어가게된다. pandas는 read_csv, read_json, read_excel 함수로 다양한 테이블형 데이터를 처리할 수 있게 해준다.
head 함수
head함수는 bash의 head와 똑같이 첫 5줄을 출력해준다. head(n=10)과 같이 원하는 줄 수를 입력할 수 있다.
columns 지정
columns에 리스트 형태로 columns를 지정할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
df_data.columns = [
"CRIM",
"ZN",
"INDUS",
"CHAS",
"NOX",
"RM",
"AGE",
"DIS",
"RAD",
"TAX",
"PTRATIO",
"B",
"LSTAT",
"MEDV",
]
df_data.head()
values
values라는 property를 사용해 numpy.ndarray 타입으로 읽을 수있다.
1
df_data.values
pandas의 구성
DataFrame과 Series가 있는데 DataFrame은 테이블 전체를 포함하는 object이고, Series는 DataFrame중 하나의Column에 해당하는 object이다.
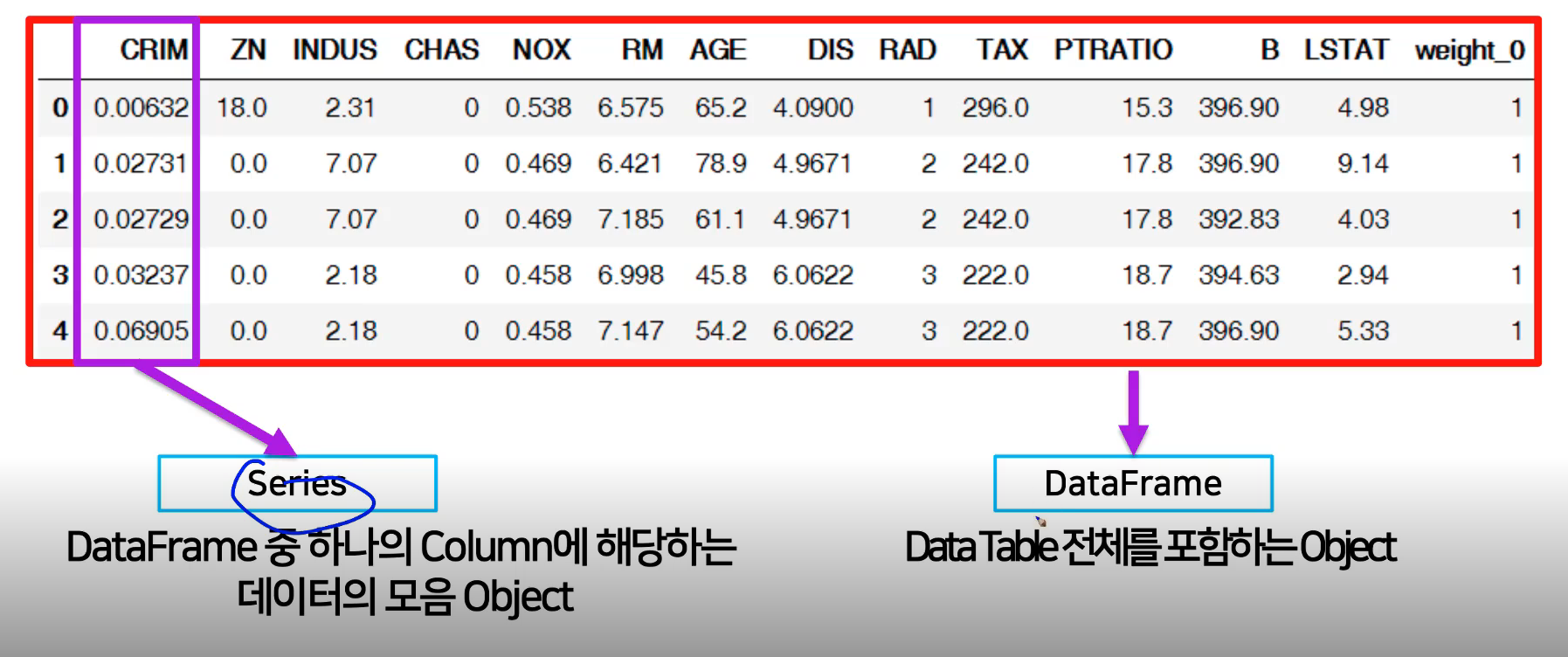
Series
Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False,)
하나의 column vector를 표현하는 object를 series라고 한다. series객체는 index도 함께 저장하고 있기때문에 아래의 코드처럼 index를 직접 지정할 수 있다. 또한 dict_type을 data로 넣게 되면 key가 index로 설정된다. index를 지정하지 않으면 0부터 차례대로 들어가게된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import pandas as pd
from pandas import Series, DataFrame
list_data = [1,2,3,4,5]
list_name = ['a','b','c','d','e']
series_obj = Series(data = list_data, index = list_name)
print(series_obj)
## output
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64
print(series_obj['c'])
## output
# 3
index, values property를 사용하여 각각 index와 value에 접근할 수 있다.
1 2 3 4 5
series_obj.values # array([1, 2, 3, 4, 5], dtype=int64) series_obj.index # Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
astype함수를 사용해 data_type를 변경할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
import pandas as pd from pandas import Series, DataFrame dict_data = {'a':1, 'b':2, 'c':3, 'd':4} series_obj = Series(data = dict_data, dtype = float, name="test") print(series_obj) ## output # a 1.0 # b 2.0 # c 3.0 # d 4.0 # Name: test, dtype: float64 series_obj = series_obj.astype(int) print(series_obj) ## output # a 1 # b 2 # c 3 # d 4 # Name: test, dtype: int32
DataFrame
DataFrame(data=None, index = None, columns = None, dtype = None, copy: 'bool' = False,)
Data Frame는 Data Table전체를 포함하는 object이다. 보통 DataFrame를 직접 호출해서 사용하는 경우는 거의 없다. 보통 CSV나 Excel파일을 읽어서 처리한다.
1
2
3
4
5
6
import pandas as pd
from pandas import Series, DataFrame
raw_data = {"num":[1,2,3,4,5], "test1":["abc","bcd","cde","def","efg"], "test2":["111","222","333","444","555"]}
DataFrame(raw_data, columns = ["num", "test2"])
DataFrame(raw_data, columns = ["num", "test2", "test3"])
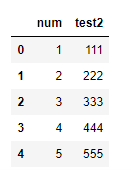
특정 columns를 명시해서 해당 columns만을 가지는 dataframe을 만들 수 있다. 만약 존재하지 않는 columns를 작성하게 되면 해당 columns가 추가되고 NaN값으로 초기화 된다.
dataframe객체에서 column이름으로 series를 추출 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
df = DataFrame(raw_data, columns = ["num", "test2"])
df.test2
# df["test2"]둘다 똑같다.
# 0 111
# 1 222
# 2 333
# 3 444
# 4 555
# Name: test2, dtype: object
df[df["test2"] == 111]
df[df["num"] > 3]
# 이렇게 특정 조건을 넣어서 해당 조건을 만족하는 DF만 추출할 수 있다.
DataFrame의 경우index와 columns property를 사용해 index 혹은 column만 추출할 수 있다.
1
2
3
4
df_data.index
# Index(['4', '3', '2', '1', '5'], dtype='object')
df_data.columns
# Index(['first_name', 'last_name', 'age', 'city'], dtype='object')
Series indexing
indexing에는 loc, iloc가 있다. loc은 접근을 할 때 index의 이름을 기준으로 접근을 하는것이고, iloc는 index의 순서 번호로 접근을 하는 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
s = pd.Series(np.nan, index=[49,48,46,1,2,3])
s.loc[:3]
# 49 NaN
# 48 NaN
# 46 NaN
# 1 NaN
# 2 NaN
# 3 NaN
# dtype: float64
s.iloc[:3]
# 49 NaN
# 48 NaN
# 46 NaN
# dtype: float64
loc는 index의 name을 기준으로 접근을 하기 때문에 3이라는 index name을 가진 데이터까지 슬라이싱 되었다. 하지만 iloc는 index의 순서 번호로 접근하기 때문에 3번째 index인 46까지 출력된 것을 볼 수 있다. loc혹은 iloc를 명시하지 않고 슬라이싱을 하게되면 iloc를 한것과 같은 결과가 나온다.
index list
접근하고 싶은 index name을 리스트로 접근할 수 있다.
1 2 3 4 5 6
s = Series(data = [1,2,3,4,5,6], index=[49,47,46,1,2,3]) s[[1,2,3]] # 1 4 # 2 5 # 3 6 # dtype: int64
boolean indexing
조건을 넣어 조건에 맞는 data만 추출할 수 있다.
1 2 3 4 5 6 7 8
s = Series(data = [1,2,13,4,5,6], index=[49,47,46,1,2,3]) s[s<10] # 49 1 # 47 2 # 1 4 # 2 5 # 3 6 # dtype: int64
DataFrame indexing
DataFrame에서 Series추출
DataFrame을 column명으로 접근해 Series를 추출할 수 있다. 이때 반환된는 타입은 Series이기 때문에 Series의 indexing을 사용할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
import pandas as pd import numpy as np from pandas import Series, DataFrame raw_data = { "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"], "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"], "age": [42, 52, 36, 24, 73], "city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"], "sex" :["male","female","male","male","female"] } df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city"]) s = df["first_name"] # 0 Jason # 1 Molly # 2 Tina # 3 Jake # 4 Amy # Name: first_name, dtype: object
index list
series와 마찬가지로 접근하고 싶은 column을 list로 만들어 접근할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import pandas as pd import numpy as np from pandas import Series, DataFrame raw_data = { "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"], "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"], "age": [42, 52, 36, 24, 73], "city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"], "sex" :["male","female","male","male","female"] } df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city"]) df[["first_name", "city"]]
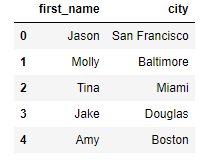
이때 반환 타입은 DataFrame이기 때문에 index로 바로 Series처럼 사용하면 안된다.
DataFrame 슬라이싱
1
df[["first_name", "city"]][:3] #DataFrame타입이기 때문에 [3]으로 접근불가
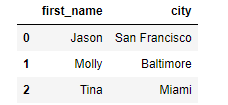
DataFrame loc
DataFrame에서도 loc는 index의 이름을 기준으로 접근할 수 있게 해준다. column을 통한 접근과 다르게 index를 기준으로 추출해준다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
import pandas as pd import numpy as np from pandas import Series, DataFrame raw_data = { "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"], "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"], "age": [42, 52, 36, 24, 73], "city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"], "sex" :["male","female","male","male","female"] } index_list = list("43215") df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city"]) # 동작 비교를 위해 index추가 df.index = index_list df.loc["4"] # Series type # first_name Jason # last_name Miller # age 42 # city San Francisco # Name: 4, dtype: object df.loc[["4","3","2"]]
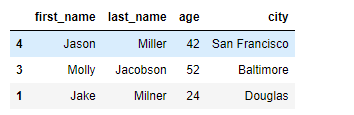
index list를 통한 접근은 DataFrame를 반환하므로 다시 column 기준으로 원하는 데이터만 뽑을 수 있다.
1
2
3
4
df.loc[["4","3","1"]][["first_name","city"]]
# df.loc[["4","3","1"]]["first_name"]
# 주석 처리된 코드는 4,3,1 index만 추출된 DataFrame에서 first_name column만
# Series Type으로 추출된다.
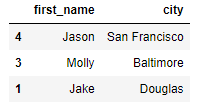
DataFrame iloc
1 2
df.iloc[0:2,0:3] # 행부터 체크해서 # 0,1번 행의 0,1,2번 열을 출력
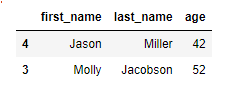
주의!!
슬라이싱을 할때, index list로 접근할 때, 그냥 index로 접근할 때 나오는 type이 무엇인지 잘 생각해야한다.
df.iloc[0:2, 0:3]같은 경우 type이 DataFrame이지만df.iloc[0,0:3]혹은df.iloc[0:3,1]은 type이 Series이고df.iloc[0,0]인 경우 type이 str이다.
DataFrame 함수, 활용
column에 새로운 데이터 할당
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import pandas as pd import numpy as np from pandas import Series, DataFrame raw_data = { "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"], "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"], "age": [42, 52, 36, 24, 73], "city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"], "sex" :["male","female","male","male","female"] } df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "sex", "debt"]) df.debt = df.age > 40 # columns에 debt를 추가하지않고 df["debt"] = df.age>40 과 같이 사용하면 # debt column이 생성되고, 같은 결과를 얻을 수 있다.
DataFrame를 생성할 때 “debt”라는 column을 추가해주었다. Series와 마찬가지로 없는 Columns은 NaN값으로 채워지는데
df.debt = df.age > 40을 통해 debt에 새로운 값을 할당해 주었다.
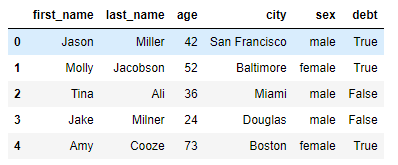
Series를 사용해 값 할당
이 경우 기존 DF에 존재하는 index를 Series에서 찾아 값을 넣는 것이기 때문에 DF에는 있고 Serise에 없는 index에는 NaN이 들어가고, Series에는 있고 DF에 없는 index는 무시된다.
1 2 3 4
df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "sex"]) values = Series(data=["M","F","F","M"], index=[0,1,3,123]) df["sex"] = values
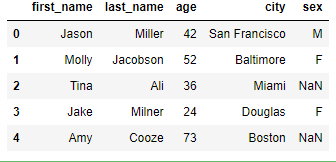
Transpose
df.T를 사용해 전치된 DataFrame을 볼 수 있다.to_csv
csv 포맷으로 변경해준다.
1 2
df.to_csv() # ',first_name,last_name,age,city,sex\r\n0,Jason,Miller,42,San Francisco,M\r\n1,Molly,Jacobson,52,Baltimore,F\r\n2,Tina,Ali,36,Miami,\r\n3,Jake,Milner,24,Douglas,F\r\n4,Amy,Cooze,73,Boston,\r\n'
del
기존의 값을 삭제 원본 DataFrame자체가 변경된다.
1
del df["first_name"]
reset_index
index를 초기화 시킨다. reset_index의 경우 index를 0부터 시작하는 오름차순 index로 초기화 시킨다. 옵션을 주어 기존 index를 삭제할 수 있고, 아닐경우 새로운 index가 추가된다. reset_index는 del과 다르게 원본 DataFrame을 변경하지 않는다. 원본 DataFrame를 변경하려면 inplace=True를 사용해야한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import pandas as pd import numpy as np from pandas import Series, DataFrame raw_data = { "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"], "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"], "age": [42, 52, 36, 24, 73], "city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"], "sex" :["male","female","male","male","female"] } df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "sex"]) df.index = list("54321") df.reset_index(drop=True) # 원본 dataframe은 그대로 df.reset_index(inplace=True, drop=True) # 처럼 하면 원본 dataframe가 변경됨
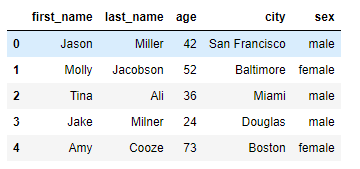
drop을 하게되면 기존 54321로 지정된 index가 사라지고, 새로운 index가 추가된다. drop을 하지 않게되면 df.reset_index() 아래와 같이 결과가 나온다.
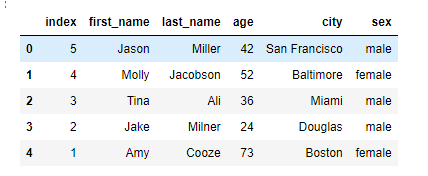
drop
index로 해당 행을 지운다.
1 2
df.drop(1) # df.drop(1, inplace=True) df.drop([1,2,3,4]) # 한번에 여러개 삭제 가능
axis를 명시해서 열을 지울수 있다.
1
df.drop("city", axis=1)
xlsx파일 읽기
xlrd모듈을 설치하여 xlsx파일을 읽을 수 있다. conda install xlrd
1 2 3 4
import pandas as pd import numpy as np df = pd.read_excel("[PATH].xlsx")
Series 연산
1
2
3
4
5
6
7
8
9
10
11
12
13
s1 = Series(range(1,6), index=list("abcde"))
s2 = Series(range(5,11), index=list("bcedef"))
s1 + s2
s1.add(s2)
# a NaN
# b 7.0
# c 9.0
# d 12.0
# e 12.0
# e 14.0
# f NaN
# dtype: float64
index를 기준으로 연산이 수행되기 떄문에 겹치는 index가 없는 경우 NaN값이 반환된다.
Dataframe 연산
1
2
3
4
5
df1 = DataFrame(np.arange(9).reshape(3,3), columns=list("abc"))
df2 = DataFrame(np.arange(16).reshape(4,4), columns=list("abcd"))
df1 + df2
df1.add(df2, fill_value=0)
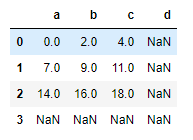
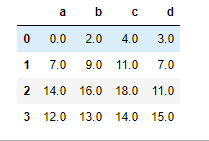
Dataframe 연산에서는 column과 index를 모두 고려한다. 연산자를 사용한 계산은 Series와 마찬가지로 겹치는 값이 없으면 NaN이 반환되고, add, sub, dic, mul같은 함수를 사용해 연산하면 겹치지 않는곳에 넣을 값을 명시할 수 있다. 위의 코드에서 fill_value=0은 df1의 모자란 부분을 0으로 채워 계산하라는 뜻이다.
Series와 Dataframe연산
1
2
3
4
df = DataFrame(np.arange(16).reshape(4,4), columns=list("abcd"))
s = Series(np.arange(10,14))
df + s
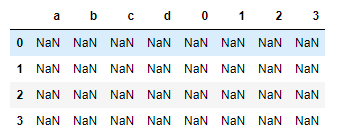
1
df.add(s, axis=0)
axis를 명시해주면 broadcasting이 실행되고 연산도 잘 된다. 참고로 df + s의 결과는
df.add(s, axis=1)의 결과와 같다.
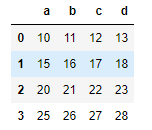
map
pandas의 series type데이터도 map함수가 사용가능하다. function대신 dict 혹은 sequence자료형으로 대체가 가능하다.
1
2
3
4
5
6
7
s = Series(np.arange(4))
s.map(lambda x: x**2)
# 0 0
# 1 1
# 2 4
# 3 9
# dtype: int64
dict자료형을 사용해 dict의 key를 index로 보고 해당 index의 data를 dict의 value로 변경할 수 있다.
1
2
3
4
5
6
7
z = {1:'A', 2:'B', 3:'C'}
s.map(z)
# 0 NaN
# 1 A
# 2 B
# 3 C
# dtype: object
다른 Series의 data로 값을 변경할 수 있다.
1
2
3
4
5
6
7
s2 = Series(np.arange(10,20))
s.map(s2)
# 0 10
# 1 11
# 2 12
# 3 13
# dtype: int32
map을 활용해 아래의 코드처럼 str타입의 성별을 int타입의 code로 변경할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
raw_data = {
"first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"],
"last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"],
"age": [42, 52, 36, 24, 73],
"city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"],
"sex" :["male","female","male","male","female"]
}
df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "sex"])
df["sex_code"] = df.sex.map({"male":0, "female":1}) # dict type적용해 replace
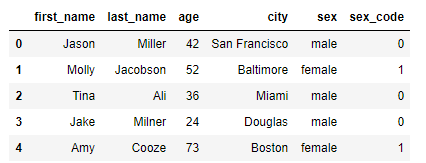
replace함수를 사용하면 map을 사용한것과 똑같이 str타입 성별을 int 타입으로 변경 가능하지만 다른 column으로 넣을 수는 없다.
1
2
3
4
df.sex.replace({"male":0,"female":1}, inplace=True)
# df.sex.replace(["male", "female"],[0,1], inplace=True)
# df["sex"] = df.sex.map({"male":0, "female":1})
# map도 위처럼 사용하면 replace와 똑같은 결과가 나온다.
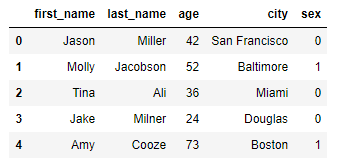
apply
map과 달리 series전체 (Column)에 해당 함수를 적용한다.
1
2
3
4
5
6
7
8
9
10
11
12
df_info = df[["age", "sex_code"]]
f = lambda x : x.max() - x.min()
df_info.apply(f)
# age 49
# sex_code 1
# dtype: int64
df_info.sum() #각 column별로 sum적용
df_info.apply(sum) #위와 같음
# age 227
# sex_code 2
# dtype: int64
scalar값 이외에 series값의 반환도 가능하다.
1
2
3
4
5
6
def f1(x):
return Series([x.min(),x.max()],index=["min","max"]
# 각 column 별로 min, max값을 구해 각각 min inde와 max index형태로 반환
df_info.apply(f1)
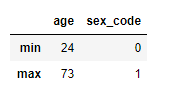
Column을 명시하면 해당 column에 함수를 적용한 결과를 반환한다.
1
2
3
4
5
6
7
8
f = lambda x : -x
df_info["age"].apply(f) # Column을 명시하면 해당 Column에 함수를 적용해 반환
# 0 -42
# 1 -52
# 2 -36
# 3 -24
# 4 -73
# Name: age, dtype: int64
applymap을 사용하여 series단위가 아닌 element단위로 함수를 적용할 수 있다.
1
2
f = lambda x : -x
df_info.applymap(f) # Column을 명시하면 해당 Column에 함수를 적용해 반환
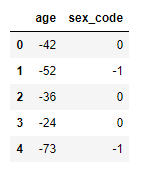
pandas built-in
descirbe
Numeric type 데이터의 요약 정보를 보여준다. 숫자형 데이터만 요약해서 보여준다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import pandas as pd import numpy as np from pandas import Series, DataFrame raw_data = { "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"], "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"], "age": [42, 52, 36, 24, 73], "city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"], "sex" :["male","female","male","male","female"] } df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "sex", "sex_code"]) df["sex_code"] = df.sex.map({"male":0, "female":1}) # dict type적용해 replace df.describe()
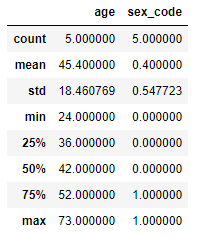
unique
seire data의 유일한 값을 list로 반환한다.
1 2
df.sex.unique() # array(['male', 'female'], dtype=object)
sum, sub, mean, min, max, count, median, mad, var
column 또는 row값의 연산을 지원한다
axis를 0으로하면 column별로 axis를 1로하면 row별로 연산이 수행된다.
isnull
NaN값인지 아닌지 True, False
df.isnull().sum()처럼 사용하여 각 column별로 NaN이 얼마나 있는지 확인할 수 있다.
sort_values
1
df.sort_values(["age","sex_code"], ascending=True)
정렬을 하고싶은 기준과 오름차순으로 할것인지 내림차순으로 할것인지 정해야한다.
False라면 내림차…
index값이 섞여서 나오게됨
corr, cov, corrwith
상관계수와 공분산을 구하는 함수
1 2 3 4 5
df.age.corr(df.earn) # 나이와 소득의 상관관계 df.age.cov(df.earn) df.corrwith(df.earn) df.corr() # 모든 column관의 상관관계를 볼 수 있음
options.display.max_rows
출력되는 양을 조절할 수 있다.