Bag-of-Word
- 단어의 순서는 고려하지 않고, 출현 빈도에 집중하는 텍스트 데이터 수치화 표현 방법이다.
- 각 단어별로 고유한 index를 부여하고, 각 index위치에 해당 단어가 등장한 횟수를 기록한 벡터를 만든다.
- Sentence : “I really really like this movie”
- I : [1, 0, 0, 0, 0], really : [0, 1, 0, 0, 0], like : [0, 0, 1, 0, 0], this : [0, 0, 0, 1, 0], movie : [0, 0, 0, 0, 1]
- Sentence : [1, 2, 1, 1, 1]
- 단어들의 상관관계는 고려하지 않았기 때문에 word끼리의 거리는 $\sqrt{2}$, 코사인 유사도는 0으로 나오는것을 알 수 있다. (모든 단어가 동일한 관계를 가지는 벡터로 변경)
NaiveBayes Classifier
- 베이즈 이론에 기반한 베이즈 분류기를 주어진 클래스의 속성값이 다른 속성과 상호 독립을 가정하여 계산과정을 단순(naive)하게만든것을 말한다.
- 문서 d와 분류해야할 class c가 있을 때 문서 d가 주어졌을 때 c일 확률을 찾아 문서를 분류할 수 있다.
첫번 째 식을 Bayes Rule을 사용해 두번 째 식과 같이 나타낼 수 있고, P(d)의 경우 특별한 문서 d가 나올 확률인데 고정된 하나의 문서로 볼 수 있으므로 상수로 볼 수 있어 가장 마지막 식이 나온다.
\(P(d|c)\) 는 특정 카테고리 C가 고정이 되었을 때 문서 d가 나타낼 확률을 의미한다. 문서 D는 각 단어들이 동시에 나타나는 사건으로 볼 수있다. 따라서 각어가 등장학 확률이 서로 독립이라고 가정할 수 있다면 각 단어가 나타날 확률을 곱해서 표현할 수 있다.
- 위의 식으로 문서가 주어지기 이전에 각 클래스가 나타날 확률과, 클래스가 고정되어 있을 때 각각의 word가 나타날 확률을 추정하는것으로 NaiveBayes Classifier에서 필요로하는 파라미터를 추정할 수 있다.
example
- 다음과 같은 Dataset들이 있다고 가정해보자.
1
2
3
4
5
6
train_set = {"Image recognition uses convolutional neural networks" : "CV",
"Transformer can be used for image classification task" : "CV",
"Language modeling uses transformer" : "NLP",
"Document classification task is language task" : "NLP"}
sentence = "Classification task uses transformer"
- sentence가 어떤 클래스에 속하는지 NaiveBayes Classifier를 사용해 추론해보자. 우선 클래스가 “CV”, “NLP”일 확률은 다음과 같다.
이제 $P(d|c)=P(w_1,…,w_n|c) \rightarrow \prod_{w_i\in W}P(w_i |c)$ 식을 사용해 각 단어가 해당 클래스에서 나오는 확률을 구해 곱해야한다.
CV클래스에 대해서 먼저 계산해보면 train_set에 CV클래스에 속하는 단어는 총 14개 이므로 sentence에 각 단어들이 CV클래스에 등장하는 횟수를 14로 나누어주면 된다.
- 이제 NLP클래스에 대해서 위와 같이 계산하면 된다.
- 각 확률을 모두 곱하면 해당 각 클래스가 될 확률을 구할 수 있다.
- 위의 식을보면 다른 모든 단어가 나타날 확률이 높아도 하나만 0이 된다면 확률 자체가 0이되는 문제가 있다는것을 알 수 있다. → Smoothing과 같은 방법을 사용해 해결한다.
word Embedding
- 단어를 특정 차원의 벡터로 표현하는 방법
- 비슷한 의미를 가지는 단어끼리는 좌표공간 상의 가까운 위치에 배정되도록 하는것이 기본 아이디어이다.
Word2Vec
- 같은 문장에서 나타난 인접한 단어들간의 의미가 비슷할 것이라는 가정을 사용한다.
- 한 단어가 주어졌을 때 주변 단어가 나타날 확률 분포를 예측한다. → 주변 단어를 숨기고 예측하도록 하는것으로 Word2Vec학습이 진행된다.
- input sentence에 포함된 단어들을 사용해 사전을 만들고, sliding window기법을 사용해 입출력 단어 쌍을 추출한다.
- sliding window는 window를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 데이터 셋을 만드는 방법이다.
- 이렇게 추출한 입출력 단어 쌍을 사용해 입력이 주어졌을 때 출력이 나오도록 모델을 학습시킨다.
- Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram이라는 두가지 방식이 있다.
- CBOW(Continuous Bag of Words)
- 주변의 단어들을 사용해 중간에 있는 단어를 예측하는 방법
- 하나의 단어를 예측하기 위해 w * window_size 개가 입력 벡터로 사용된다.
- 4개의 결과 벡터에 대해 평균을 구하고 결과를 $W_2$행렬과 곱해 softmax를 취하고 실제 label과 cross-entropy 손실함수를 사용해 학습한다.
- Skip-Gram
- 중간의 단어를 사용해 주변 단어들을 예측하는 방법
- 중심 단어에 대해서 주변 단어들을 예측하므로 CBOW처럼 평균을 구하는 과정은 없다.
- CBOW(Continuous Bag of Words)
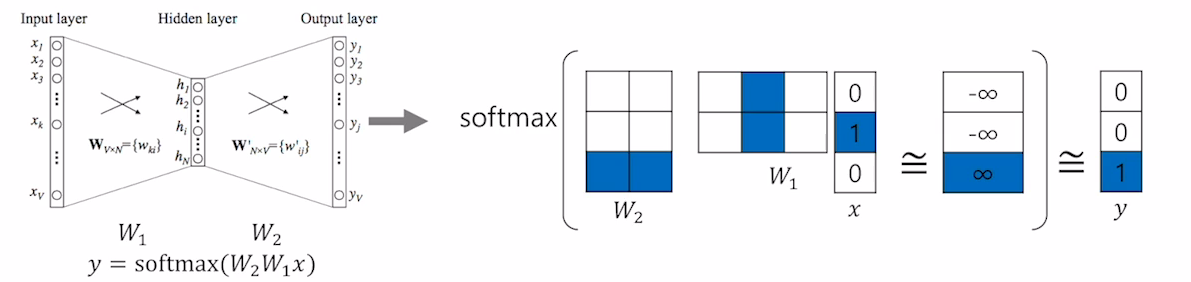
- Word2Vec는 딥러닝 모델이 아니다. 하나의 hidden Layer만 존재하고, 활성화 함수또한 사용되지 않는다. 일반적인 hidden Layer와 구분하기 위해 projection layer라고 부르기도 한다.
- 입력 x는 one hot vector이므로 i번째 인덱스만 1이라는 값을 가지고 나머지는 0을가진다. 따라서 입력 벡터와 가중치 행렬의 곱은 W행렬의 i번째 행을 읽어오는 것과 똑같으며 이러한 작업을 lookup table이라고 한다.
- 주어진 입력 단어의 $W_1$상에서의 벡터와 출력 단어의 $W_2$상에서의 벡터간의 내적에 기반한 유사도가 최대한 커지게하고, 다른 단어들의 $W_2$상에서의 벡터간의 내적에 기반한 유사도는 최대한 작게 만드는것으로 학습을 진행한다.
- 이렇게 학습한 뒤 $W_1$의 행벡터 혹은 $W_2$의 열벡터를 embedding vector로 사용한다.
- 평균치를 가지고 embedding vector를 선택하기도 한다.
GloVe : Global Vectors for Word Representation
- Word2Vec와 차이점은 윈도우 내에서 각 input, output이 몇번 동시에 나타났는지 사전에 미리 계산을 한 뒤 이에 log값을 취해 빼는것으로 불필요한 연산을 줄인다.
- 임베딩 된 중심단어 벡터와 주변단어 벡터의 내적이 전체 문장에서의 동시 등장 확률이 되도록 만든다.
전처리
코퍼스 데이터는 필요에 맞게 전처리가 되어야한다. 전처리란 데이터를 용도에 맞게 tokenization, cleaning, normalization하는것을 말한다.
토큰화(Tokenization)
토큰화는 토큰이라 불리는 단위로 나누는 작업을 말한다. 토큰화의 경우 단순히 공백으로 나누는 것이 아니라 토크나이저에 따라 특별한 기준으로 토큰을 나눈다. 이러한 기준은 데이터를 어떤 용도로 사용할 것인가에 따라 용도에 영향이 없는 기준으로 정한다.
- 토큰화 고려할 점
- 특수문자를 단순 제거해서는 안된다.
02/17과 같이 날짜를 표현하는 문자 처럼 특수문자를 지우는것으로 원래의 의미를 알 수 없는 경우가 생긴다. 혹은 마침표가 없을 경우 어디가 문자의 끝인지 알 수 없게된다.
줄임말과 단어 사이에 띄어쓰기가 있는경우
New York과 같이 한 단어이지만 띄어쓰가 존재하는 단어와, i’m 과 같이 줄임말을 i am과 구분할 필요가 있는지도 확인해야한다. i’m의 m을 접어라고 한다.
정제(Cleaning)
갖고 있는 코퍼스로부터 노이즈 데이터를 제거하는것을 말한다.
Cleaning에서 노이즈 데이터란 아무런 의미를 가지지 않는 글자 혹은 분석하고자 하는 목적에 맞지 않는 불필요한 단어들을 말한다.
정규화(normalization)
표현방법이 다른 단어들을 통합시켜 같은 단어로 만드는 작업을 말한다. 예를 들어 대소문자를 통합하는것도 하나의 정규화이다.
어간 추출(Stemming)
어간 추출은 말그대로 정해진 규칙대로 단어의 어미를 자르는 작업이다. 알고리즘에 따라 사전에 존재하지 않는 단어가 나올 수 있다.
표제어 추출(Lemmatization)
표제어란 쉬운 말로 기본 사전형 단어라고 말할 수 있다. 표제어 추출은 어근 단어를 찾아준다. 예를들어 is, are의경우 be가 표제어가 된다. 이러한 표제어 추출 작업은 어간과 접사를 분리하는 형태학적 파싱을 먼저 진행한다.
표제어 추출도 경우에 따라서 사전에 없는 단어가 나올 수 있다. 이러한 이유는 표제어 추출기가 본래 단어의 품사 정보를 알고 있어야한 정확한 결과를 얻을 수 있기 때문이다.
Stemming과 차이
Lemmatization는 문맥을 고려하며 수행했을 때의 결과는 해당 단어의 품사정보를 보존한다.
Stemming을 수행한 결과는 품사 정보가 보존되지 않는다.(POS tag)
불용어(Stopword)
불용어란 자주 등장하지만 분석을 하는것에 도움이 되지 않는 단어를 말한다.
영어 전처리
spacy라는 패키지를 사용해 영어 뿐만 아니라 독일어, 일본어 등 다양한 나라의 언어를 쉽게 사용하도록 도와준다. 설치는 아래의 같다.
1
2
conda install -c conda-forge spacy
python -m spacy download en
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import spacy
nlp = spacy.load('en_core_web_sm') # 원하는 언어모델로 객체 생성
word = nlp("Use Control-C stop this server and shut down all kernels")
type(word) # spacy.tokens.doc.Doc
list(word) # [Use, Control, -, C, stop, this, server, and, shut, down, all, kernels]
for token in word:
print(token.is_stop) # is_stop으로 토큰이 불용어 인지 확인할 수 있음
# False
# False
# False
# False
# False
# True
# ...
for token in word:
print(token.lemma_) # 표제어 추출
# use
# Control
# -
# C
# stop
# this
# server
# and
# shut
# down
# all
# kernel
위의 코드 이외에도 is_punct(문장 부호인지) is_space(공백인지)등 다양한 속섣들이 있다.
https://spacy.io/api/token#attributes
한국어 전처리
konlpy를 사용해 한국어를 처리할 수 있다.
1
2
3
4
5
6
7
from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
mecab = Mecab()
okt = Okt()
위와같이 여러개의 형태소 분석, 태깅 라이브러리를 클래스 형태로 사용할 수 있다. 이 클래스들은 nouns, morphs, pos라는 공통 매서드를 가지고있다.
- nonus : 명사 추출
- morphs : 형태소 추출
- pos : 품사 부착