one to one
- Standard NN
one to many
image Captioning
![RNN0]()
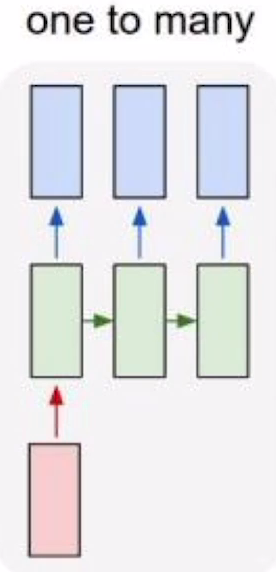
이렇게 입력이 하나일 경우 다른 time의 입력값으로는 처음 입력값과 같은 크기지만 모든 값이 0으로 채워진 텐서를 준다.
many to one
sentiment classification
![RNN1]()
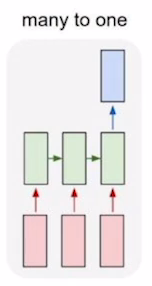
마지막 time에서 나온 h에 output Layer를 적용하는것으로 최종 결과를 얻는다.
many to many
machine translation
![RNN2]()
Video classification on frame level
![RNN3]()
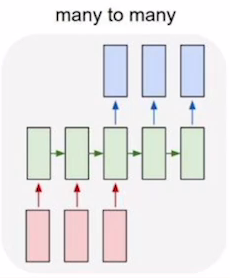
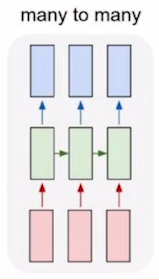
마지막 time에서 나온 h에 output Layer를 적용하는것으로 최종 결과를 얻는다.
Backpropagation through time (BPTT)
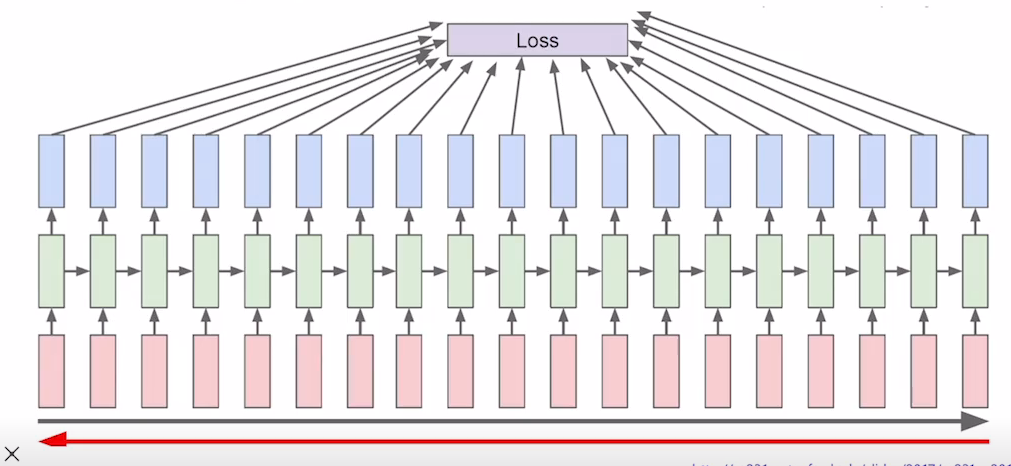
- input sequence가 매우 길 경우 적당한 크기로 잘라서(truncation) 학습을 진행한다.
Vanishing/Exploding Gradient problem in RNN
- original, vanilla RNN에서는 동일한 matrix를 매 time step마다 곱하게 되므로 길이가 길어질 수록 Gradient Vanishing혹은 Exploding문제가 발생한다.
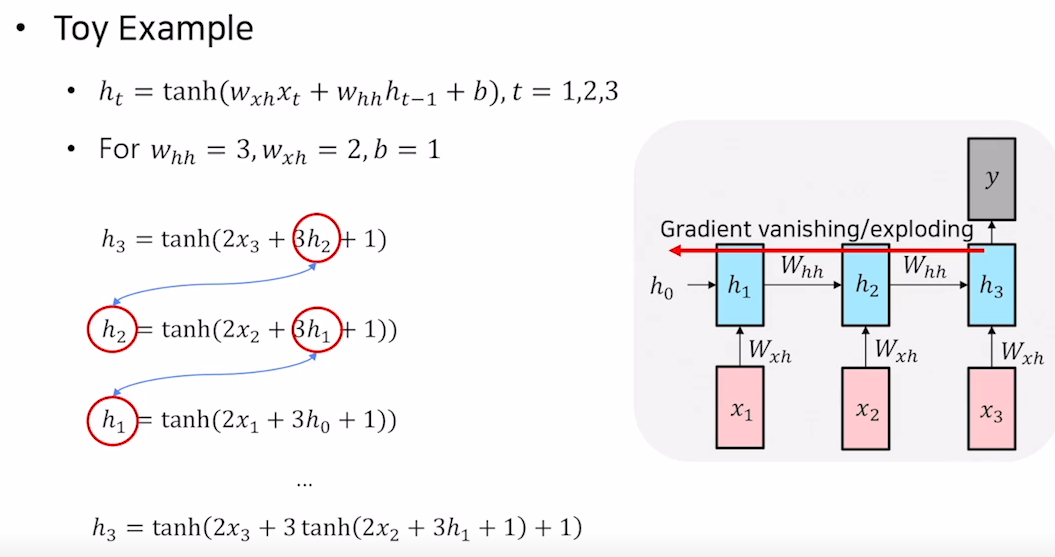
위의 예에서 3이라는 w값이 계속해서 곱해져 Gradient가 Exploding될 수 있다. 최근에는 vanilla RNN은 거의 사용하지 않는다.
LSTM(Long Short-Term Memory)
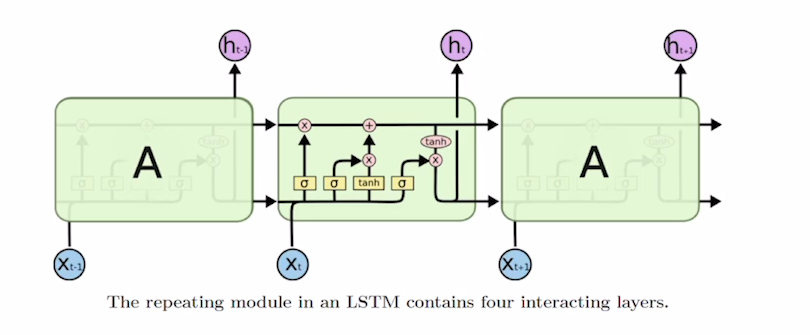
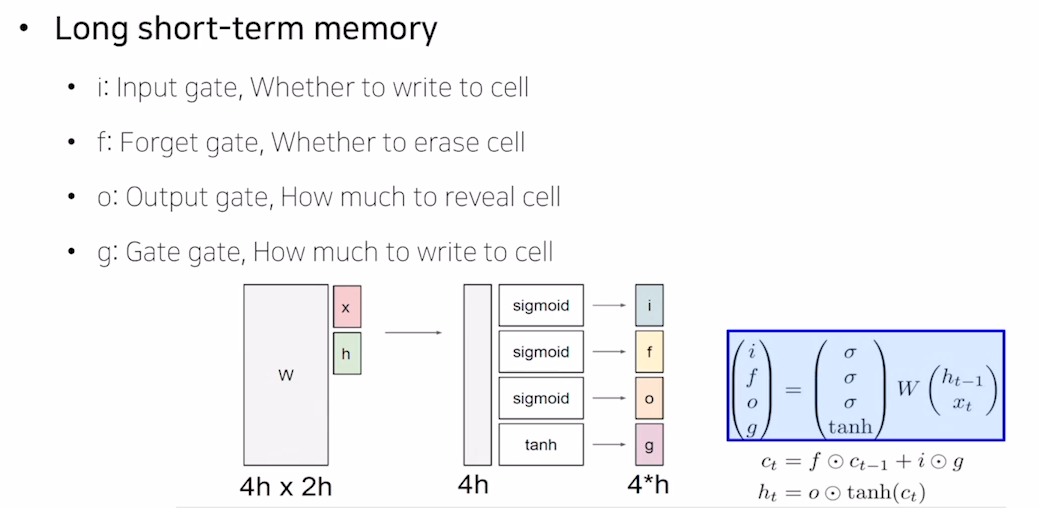
참고
Sigmoid를 취한 결과를 특정 벡터에 곱하는것은 원래 가지던 값을 특정한 비율만 사용할 수 있도록 해준다.
- vanilla RNN의 input이 길어지면서 생기는 문제점을 해결하기 위해 등장하였다.
- Cell State Vector, Hidden State Vector 두개의 Vector를 사용해 이전 정보를 고려한다.
- Cell State : 기억해야하는 모든 정보를 담고 있는 Vector
- Hidden State : 현재 time step에 필요한 정보만 Cell State 필터링한 Vector
Forget gate
이전에서 넘어온 Cell State에 hidden state와 input x에 Sigmoid를 취한 vector를 Element wise 곱셈을 하는것으로 특정 비율만큼만 고려하게한다. (특정 비율을 잊게 한다)
Input gate, Gate gate
그림을 보면 Sigmoid를 취한 결과와, tanh를 취한 결과를 곱해 forget gate를 통과한 Cell State에 더해지는것을 볼 수 있다. 이 부분은 이전 hidden state와 현재 입력을 고려해 현재의 정보중에서 어느정도를 고려해 Cell State에 추가할지를 정하는 것이다.
\[i_t = \sigma(W_i\cdot[h_{t-1, x_t}]+b_i)\\\tilde{C_t}=tanh(W_c\cdot [h_{t-1},x_t] +b_c)\\C_t = f_t\cdot C_{t-1}+i_t\cdot \tilde{C_t}\]Output Gate
\[o_t=\sigma(W_o[h_{t-1}, x_t] + b_o)\\h_t=o_t\cdot tanh(C_t)\]
GRU(Gated Recurrent Unit)

- LSTM을 개선하여 적은 메모리 사용, 빠른 학습이 가능하도록 경량화 한 모델이다.
- LSTM에서의 Cell State와 Hidden State를 하나의 h로 사용하는데 GRU의 h는 LSTM의 Cell State와 유사한 역할을 한다
- $h_t$의 업데이트 식을 살펴보면 input gate만 사용하고 forget gate위치에는 1 - input gate를 사용한다.
LSTM, GRU의 backpropagation
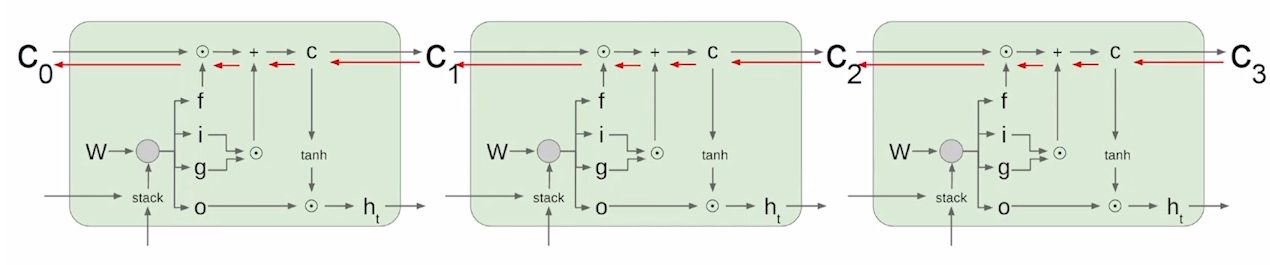
Cell State를 Update하는 과정이 덧셈에 기반하기 때문에 Gradient Vanishing/Exploding 문제를 해결할 수 있다.