통계학
- 통계적 모델링은 적절한 가정 위에서 확률분포를 추정(inference)하는 것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표이다.
- 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정할 수 밖에없다.
- 예측모형의 목적은 분포를 정확하게 맞추는 것보다는 데이터와 추정 방법의 불확실성을 고려해 위험을 최소화하는 것이다.
모수적(parametric) 방법론
- 데이터가 특정 확률분포를 따른다고 선험적으로 가정한 후 그 분포를 결정하는 모수(parameter)를 추정하는 방법을 모수적 방법론이라고 한다.
- 예를들어 정규분포를 가지고 확률분포를 모델링한다면 정규분포(N(μ, σ^2))의 모수인 평균(μ)과 분산(σ^2)을 추정하는 방법을 통해 데이터를 학습하는것을 모수적 방법론이라한다.
비모수(nonparametric) 방법론
- 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수 방법론이라고 한다
- 기계학습의 많은 방법론은 비모수 방법론에 속한다.
- 비모수 방법론은 모수가 없는것이 아닌 모수가 무수히 많거나 모수의 개수가 데이터에 따라 달라지는것이다.
확률분포 가정하기
- 데이터의 히스토그램, 통계치 등등을 보고 전체적인 모양을 관찰해 확률분포를 가정한다.
- 가정예시
- 데이터가 2개의 값(0 또는 1)만 가지는 경우 → 베르누이분포
- 데이터가 n개의 이산적인 값을 가지는 경우 → 카테고리분포
- 데이터가 [0,1]사이에서 값을 가지는 경우 → 베타분포
- 데이터가 0 이상의 값을 가지는 경우 → 감마분포, 로그정규분포 등
- 데이터가 ℝ전체에서 값을 가지는 경우 → 정규분포, 라플라스분포 등
- 위의 예시처럼 기계적으로 확률분포를 가정해서는 안되며, 데이터를 생성하는 원리를 먼저 고려하는것이 원칙이다.
- 분포를 가정했다면 각 분포마다 검정하는 방법이 있으므로 모수를 추정한 후에 반드시 검정을 해야한다.
데이터로 모수 추정하기
- 데이터의 확률분포를 가정했다면 모수를 추정해볼 수 있다.
정규분포로 모수 추정해보기
정규분포의 모수는 평균 평균(μ)과 분산(σ^2)이다. 이는 모집단의 평균과 분산인데 실제 우리가 관찰한 데이터는 표본이므로 표본 평균, 표본 분산을 추정해야하고, 이 두가지를 추정하는 통계량은 아래의 식과 같다.
표본 평균
주어진 데이터의 산술 평균을 계산한다. 이렇게 계산한 표본집단의 평균의 기대값은 모집단의 평균과 일치한다.
\[\bar{X} = \frac{1}{N}\displaystyle\sum_{i=1}^N X_i, ~~~~~~~𝔼[\bar{X}]=\mu\]표본 분산
주어진 데이터에서 표본 평균을 빼서 제곱한 뒤 산술평균 계산한다. 표본 분산의 기대값이 원래 모집단의 분산과 일치하게 된다. N이 아닌 N-1로 나누는 이유는 unbiased 추정량을 구하기 위해서이다.
\[S^2=\frac{1}{N-1}\displaystyle\sum_{i=1}^N(X_{i}-\bar{X})^2, ~~~~ 𝔼[S^2]=\sigma^2\]- 통계량(표본평균, 표본분산)의 확률분포를 표집분포(sampling distribution)라 부르며, 특히 표본평균의 표집분포는 N이 커질수록(데이터 많이 모을수록) 정규분포를 따른다.(중심극한정리, Central Limit T.), 모집단의 분포가 정규분포를 따르지않아도 성립한다.
표본분포 (sample distribution)
표본분포(sample distribution)는 말그대로 모집단에서 표본의 분포를 말한다. 따라서 모집단이 정규분포를 따르지 않는다면 표본분포 또한 정규분포를 따르지 않는다.
최대가능도 추정법(Maximum likelihood estimation, MLE)
위에서는 정규분포로 가정하여 표본평균, 표본분산을 모수로하였지만 확률분포마다 사용하는 모수가 다르므로 적절한 통계량이 달라지게된다.
가능도 함수
- 원래 확률밀도함수는 모수 θ가 주어졌을 때 x에 대한 함수로 해석하지만 가능도 함수는 주어진 데이터 x에 대해서 θ를 변수로 둔 함수이다.
- 데이터가 주어져있는 상황에서 θ에따라 값이 바뀌는 함수
- 모수 θ를 따르는 분포가 데이터 x를 관찰할 가능성을 뜻하게된다.(확률로 해석하면 안됨)
- 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나는 최대가능도 추정법이다.
- 데이터 집합 X의 행벡터가 독립적으로 추출되었을 경우 확률 밀도,질량함수의 곱으로 표현할 수 있다. \(L(\theta;\textbf{X})=\displaystyle\prod_{i=1}^n P(\textbf{x}_{i}|\theta)\) 이 경우 로그함수의 성질(곱을 덧셈으로 변경)을 사용해 다음 식처럼 변경할 수 있다. $logL(\theta;\textbf{X}) =\displaystyle\sum_{i=1}^n logP(\textbf{x}_i|\theta)$ 이렇게 데이터가 독립적으로 추출되었다면 확률함수의 곱셈이아닌 덧셈으로 최적화를 할 수 있다.
로그가능도 (log likelihood)
- 데이터의 숫자가 수억 단위가 될 경우 곱셈을 컴퓨터의 정확도로 가능도를 계산할 수 없다.
- 데이터가 독립일 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 변경할 수 있기 때문에 컴퓨터로도 연산이 가능해진다.
- 경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하는데 로그 가능도를 사용하면 연산량을 O(n^2)에서 O(n)으로 줄일 수 있다.
- 보통 손실함수의 경우 경사하강법을 사용하므로 음의 로그가능도를 최적화하게 된다(그냥 로그 가능도의 경우 최대값을 찾아주기 때문).
최대가능도 추정법 예제 (정규분포)
- 정규분포를 따르는 확률변수 X로부터 독립적인 표본{x1,…,xn}를 얻었을 때 최대가능도 추정법을 이용해 모수를 추정해보기 (likelihood함수를 최적화하는 세타를 찾기)
- 정규분포의 경우 모수로 평균과 분산을 가지기 때문에 위의 식은 아래처럼 표현할 수 있다(로그 가능도 사용).
$\theta=(\mu,\sigma)$에 대해서 $-\frac{n}{2}log2\pi\sigma^2-\displaystyle\sum_{i=1}^n\frac{|x_{i}-\mu|^2}{2\sigma^2}$ 를 미분해서 최적화를 할 수 있다.
평균으로 미분
- 표준편차로 미분
- 두 미분이 모두 0이 되는 평균과 표준편차를 찾으면 가능도를 최대화하게 된다. 가능도함수를 최대화하는 평균과 분산을 구해보면 아래와 같이 나오는것을 확인할 수 있고 이 식은 표본 평균, 표본 분산과 일치하는것을 볼 수 있다. 다만 MLE는 불편 추정량을 보장하지 않는다.
최대가능도 추정법 예제 (카테고리 분포)
- 카테고리 분포
- 카테고리 분포는 이산확률 분포이다. 베르누이분포(2개의 값중 1개를 선택하는)를 다차원으로 확장한 개념
- 카테고리 분포의 모수인 p1, p2..들은 각 차원에서 값이 1 혹은 0이될 확률을 의미한다. 따라서 p들을 모두 합치면 1이된다.
- 카테고리 분포를 Multinoulli(x; p1,p2…pd) 따르는 확률변수 X로부터 독립적인 표본 {x1, …, xn}을 얻었을 때 최대 가능도 추정법을 이용해 모수를 추정하자.
- $p_{k}^{x_{i,k}}$는 주어진 데이터 $x_{i}$의 k번째 차원에 해당하는값을 승수를 취한것이다. 각 차원별로 0과 1만 가질 수 있으므로 $x_{i,k}$는 0혹은 1을 가지게된다. 이때 $x_{i,k}$가 0이 된다면 $p_{k}^{x_{i,k}}$가 1이될것이고, $x_{i,k}$가 1이 된다면 $p_{k}$가 될것이다. 주의할 점은 $\displaystyle\sum_{k=1}^dp_{k}=1$을 만족해야한다.
$log(\displaystyle\prod_{i=1}^n\displaystyle\prod_{k=1}^d p_{k}^{x_{i,k}})$는 log의 성질을 사용하여 곱셈은 덧셈으로 바꿀 수 있으므로 다음과 같은 식으로 다시 작성할 수 있다.
\[\displaystyle\sum_{i=1}^n(\displaystyle\sum_{k=1}^d x_{i,k})logp_{k}\]위의 식에서 $\displaystyle\sum_{k=1}^d x_{i,k}$은 각 데이터들에 대해서 값이 1인 갯수를 카운팅하는 $n_k$로 대체할 수 있다.
\[\displaystyle\sum_{i=1}^n(\displaystyle\sum_{k=1}^d x_{i,k})logp_{k}=\displaystyle\sum_{i=1}^nn_klogp_{k}\]$\displaystyle\sum_{k=1}^dp_{k}=1$를 만족하면서 위의 목적식을 최대화하는 것이 우리가 구하려는MLE이다.
이렇게 제약식이 있는 경우 라그랑주 승수법을 통해 최적화 문제를 풀 수 있다.
\[L(p_{1},...,p_{k},\lambda)=\displaystyle\sum_{k=1}^dn_{k}logp_{k}+\lambda(1-\displaystyle\sum_{k}p_{k})\]최종적으로 위의 식을 최적화하는것으로 제약식을 만족하며 주어진 가능도를 최대화 시키는 모수 p1 ~ pk까지를 구할 수 있다.
위의 목적식을 각 p들과, $\lambda$로 미분하여 각 미분값이 0이되어야 가능도가 최대가된다.
- pk로 미분 : $\frac{\partial{}L}{\partial {p_{k}}}=\frac{n_k}{p_k}-\lambda$
- $\lambda$로 미분 : $\frac{\partial{}L}{\partial {p_{\lambda}}}=1 - \displaystyle\sum_{k=1}^dp_k$
$\lambda$로 미분한 식은 제약식과 똑같은것을 알 수 있고, pk로 미분한식을 보면 $\frac{n_k}{p_k}$가 모두 lambda와 같아야 한다는것을 알 수 있다. 이것으로 아래의 식을 유도할 수 있다.
\[p_k=\frac{n_k}{\textstyle\sum_{k=1}^dn_k}=\frac{n_k}{n}\]결과를 보면 카테고리 분포에서는 각각의 차원 데이터의 경우의 숫자를 세어 비율을 구하는것으로 최대가능도를 달성하는 모수를 추정하는것이 가능하다는 것을 알 수 있다.
딥러닝에서 최대가능도 추정법
- 딥러닝 모델의 가중치를 $\theta=(\textbf{W}^{(1)},…,\textbf{W}^{(L)})$ 표기한다면 분류문제에서 소프트맥스 벡터는 카테고리분포의 모수(p1,..,pk)를 모델링한다.
- 원핫벡터로 표현한 정답레이블 y = (y1,…,yk)를 관찰데이터로 이용해 확률분포인 소프트맥스 벡터의 로그가능도를 최적화하는 것으로 딥러닝의 모수인 $\theta$를 학습시킬 수 있다.
- 모든 클래스의 개수(k=1 ~ K)에 대해서 모든 데이터(i=1 ~ n)대해 MLP의 k번째 예측의 로그값과 정답 레이블에 포함되는 y의 k번째를 곱해준것으로 표현된다.
확률분포의 거리
- 기계학습에서 사용되는 손실함수들은 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도한다.
- MLE로 추정하는 많은 학습 방법론이 확률분포의 거리를 최적화 하는것과 밀접하게 관련이 있다.
- 데이터공간에 두 개의 확률분포 P(x), Q(x)가 있을 경우 두 확률분포 사이의 거리를 계산할 때에는 다음과 같은 함수들을 사용한다.
- 총변동 거리(Total Variation Distance, TV)
- 쿨백-라이블러 발산(Kullback-Leibler Divergence, KL)
- 바슈타인 거리(Wasserstein Distance)
쿨백-라이블러 발산
KL Divergence는 이산확률변수, 연속확률 변수에 따라 아래의 식처럼 정의한다.
이산확률변수
\[𝕂𝕃(P||Q)=\displaystyle\sum_{\textbf{x}\in X}P(\textbf{x})log(\frac{P(\textbf{x})}{Q(\textbf{x})})\]연속확률변수
- KL Divergence는 다음과 같이 두개의 엔트로피 항으로 분해할 수 있다.
- 앞의 항을 크로스엔트로피 뒤의 항을 엔트로피라고 부른다.
- 분류 문제에서 정답레이블을 P 모델예측을 Q라고하면 최대가능도에서 사용되는 손실 함수가 KL Divergence에서의 크로스 엔트로피 -를 붙힌것과 똑같게 된다.
- 따라서 최대가능도를 최적화 시키는 것과 정답레이블 확률분포 P와 모델예측 확률분포 Q사이의 거리, 즉 KL Divergence를 최소화하는것과 똑같다.
- 확률분포사이의 거리를 최소화하는 개념과 가능도를 최대화 시킨다는것이 연관되어 있다는것을 알 수있다.
- 두개의 확률분포를 최소화한다는 개념은 주어진 개념을 통해 목적으로하는 확률분포의 최적화된 모수를 구하는것과 동일한 개념이다.
베이즈 통계학
조건부 확률
A와 B의 교집합이 일어날 확률을 B가 발생했을 때 A가 발생할 조건부 확률에 B의 확률을 곱해 구할 수 있다.
\[P(A\cap B)=P(B)P(A|B)\] \[P(B|A) = \frac{P(P\cap B)}{P(A)}=P(B)\frac{P(A|B)}{P(A)}\]A가 조건부로 주어져 있을 때 B가 발생할 확률은 B가 조건부로 주어졌을 때 A가 발생할 확률을 P(A)로 나누고, P(B)를 곱해서 구할 수 있다(베이즈 정리).
베이즈 정리
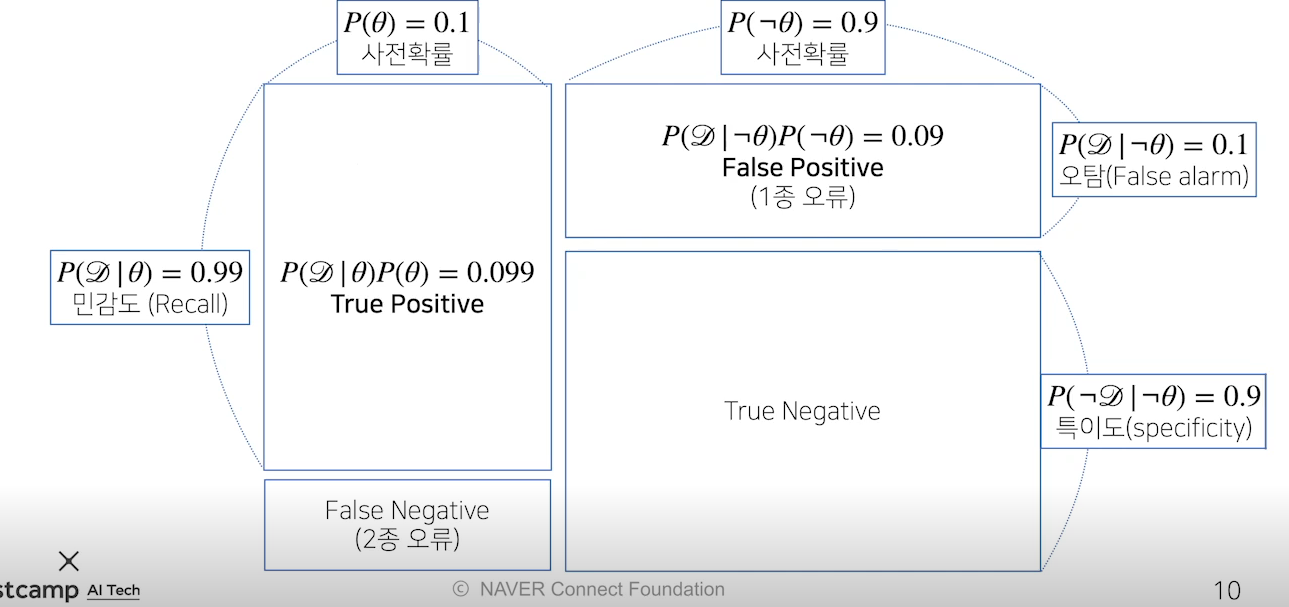
\(P(\theta|D) =P(\theta)\frac{P(D|\theta)}{P(D)}\) 의 식에서 D는 관찰한 데이터, $\theta$ 는 hypothesis, 모델의 파라미터(모수)라고 할 수 있다.
사후 확률(posterior) \(P(\theta|D)\)
데이터를 관잘했을 때 이 파라미터가 성립할 확률을 말한다. 데이터를 관찰한 이유에 측정하는 확률이기 떄문에 사후 확률이라 한다.
사전 확률(prior) $P(\theta)$
모델링하기 이전에 설정하는 확률 분포
가능도 (likelihood) $P(D|\theta)$
현재 파라미터에서 현재 데이터가 관찰될 확률
Evidence $P(D)$
데이터의 분포, 결과로써 D가 관찰될 확률
특적 조건 세타일때 D가 발생할 확률, 세타가 아닐 때 D가 발생할 확률을 더하면 D의 확률을 구할 수 있다.
베이즈 정리를 사용해 사전확률에서 사후확률로 업데이트할 수 있다. 또한 새로운 데이터가 들어왔을 때 이전 사후확률을 사전확률로 사용해 사후확률을 계속 갱신할 수 있다.
예제
![Bayes1]()
![Bayes2]()
![Bayes3]()
![Bayes4]()


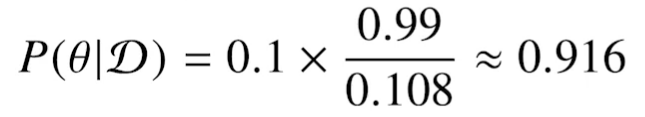
인과관계(causality)
- 인과관계는 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요하다
- 조건부 확률만 가지고 모델을 만들경우 시나리오에 따라 정확도가 크게 달라질 수 있다.
- 인과관계를 도입하게 되면 높은 예측정확도를 갖기는 힘들지만 데이터 분포변화에 강건한 예측 모델을 만들 수 있다.
- 조건부확률은 유용한 통계적 해석을 제공하지만 인과관계를 추론할 때 함부로 사용해서는 안된다. 데이터가 많아져도 조건부 확률만 가지고 인과관계를 추론하는것은 불가능하다.
- 인과관계를 알아내기 위해서는 중첩요인(Confounding factor)의 효과를 제거하고 원인에 해당하는 변수만의 인과관계를 계산해야 한다.