경사하강법
- 미분값을 더하여 함수를 증가 시키는 것을 경사상승법(gradient ascent)이라고 하며 주어진 함수의 극대값의 위치를 찾을 때 사용한다.
- 반대로 미분 값을 빼서 함수를 감소 시키는 것을 경사하강법(gradient descent)이라고 하며 함수의 극소값의 위치를 찾을 때 사용한다.
- 경사상승/경사하강법은 극값에 도달하면 미분값이 0이되어 미분값을 더해주거나 빼주어도 더 이상 움직이지 않는다.
미분(differentiation)
- 변수의 움직임에 따른 함수 값의 변화를 측정하기 위한 도구로 최적화에서 제일 많이 사용한다.
- $f’(x)=\lim\limits_{h\to0}\frac{f(x+h)-f(x)}{h}$변화율의 극한을 미분으로 정의한다.
미분은 함수의 f의 주어진 점 (x,f(x))에서의 접선 기울기를 구한다. 접선의 기울기를 알게되면 어느 방향으로 점을 이동해야 함수값이 증가/감소 되는지 알 수 있다.
→ 함수를 증가시키고 싶다면 미분값을 원래 점에서 더해주면된다. 반대로 감소시키고 싶다면 미분값을 빼주면 된다.
아래의 코드는 sympy의 diff 함수를 사용해 $x^2+2x+3$ 의 미분을 구하는 것이다.
1
2
3
4
5
import sympy as sym
from sympy.abc import x
sym.diff(sym.poly(x**2 + 2*x + 3),x)
# Poly(2𝑥+2,𝑥,𝑑𝑜𝑚𝑎𝑖𝑛=ℤ)
다항함수를 x로 미분을 하는 코드이다.
경사하강법 Algorithm
1
2
3
4
5
6
7
8
# gradient : 미분을 계산하는 함수
# init : 시작점, lr : 학습률, eps: 알고리즘 종료조건
var = init
grad = gradient(var)
while(abs(grad) > eps):
var = var - lr * grad
grad = gradient(var)
컴퓨터의경우 미분값이 정확히 0되는 것은 불가능해 eps보다 작을 경우 종료하는 조건이 필요하다.
위의 코드에서 while문 내부의 var을 계산한는 부분이 현재 점에서 미분 값을 뺀 것이다(경사하강법).
lr은 학습률인데 이를 통해 업데이트 속도를 조절할 수 있다(lr의 경우 잘못 설정할 경우 계속 극값을 찾지 못할수도 있다).
편미분(partial differentiation)
벡터가 입력인 다변수 함수의 경우 편미분을 사용한다.
\[\partial_{xi}f(x) = \lim\limits_{h\to0}\frac{f(x+he_{i})-f(x)}{h}\]위의 식에서 ei는 주어진 벡터의 i번째 벡터에만 영향을 주는 단위 벡터이다. 이 단위벡터를 사용해 x의 i번째 방향에서만 변화량을 구할 수 있다.
1
2
3
4
5
import sympy as sym
from sympy.abc import x,y
sym.diff(sym.poly(x**2 + 2*x*y + 3) + sym.cos(x + x*y),x)
# 2𝑥+2𝑦−(𝑦+1)sin(𝑥𝑦+𝑥)
각 변수 별로 편미분을 계산한 그레디언트(gradient)벡터를 이용해 경사하강법을 사용할 수 있다.
그레디언트 벡터 : $\nabla f = (\partial_{x1}f,\partial_{x2}f,…,\partial_{xd}f)$
그레디언트 벡터를 사용하면 변수 $x = (x_{1},x_{2},..,x_{d})$를 동시에 업데이트 할 수 있다.
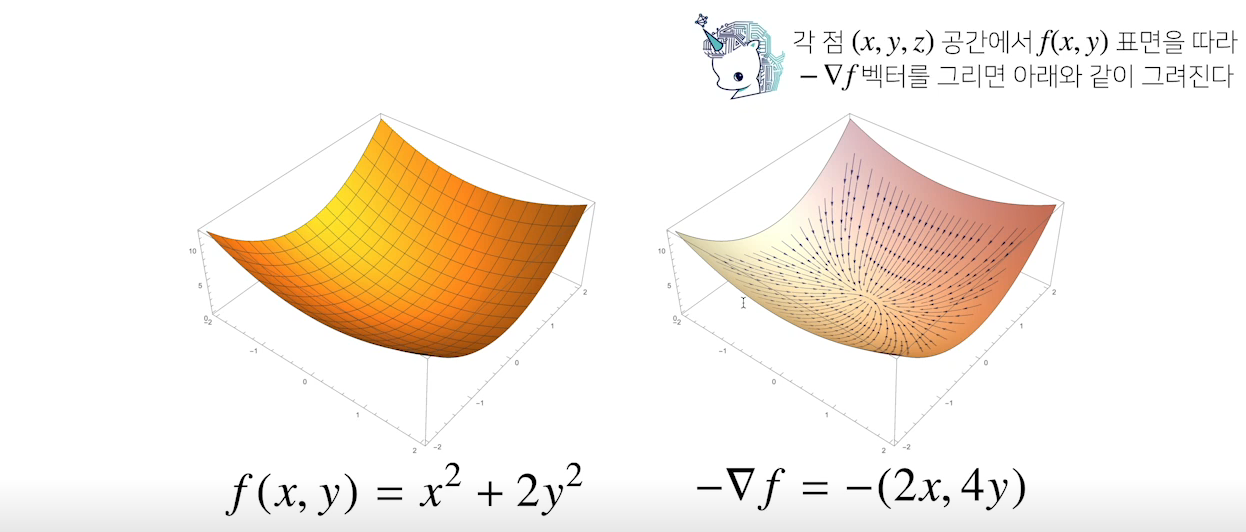
$-\nabla f$벡터를 따라가면 어떤 점에서 출발하여도 극소점으로 향하는 방향을 알 수 있다.
벡터의 경사하강법 알고리즘
1
2
3
4
5
6
7
8
# gradient : 그레디언트 벡터를 계산하는 함수
# init : 시작점, lr : 학습률, eps: 알고리즘 종료조건
var = init
grad = gradient(var)
while(norm(grad) > eps):
var = var - lr * grad
grad = gradient(var)
벡터의 경우 절대값을 계산할 수 없기 떄문에 norm을 계산하여 종료 조건을 확인하고, gradient함수는 그레디언트 벡터를 반환한다. $x^2+2y^2$를 경사하강법을 사용해 극점찾아보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import numpy as np
import sympy as sym
from sympy.abc import x,y
def eval_(fun, val):
val_x, val_y = val
fun_eval = fun.subs(x, val_x,).subs(y,val_y) # sympy의 subs함수는 특정 변수에 특정 값을 넣어주는 것이다.
return fun_eval
def func_multi(val):
x_, y_ = val
func = sym.poly(x**2 + 2*y**2)
return eval_(func, [x_, y_]),func
def func_gradient(fun, val):
x_, y_ = val
_, function = fun(val)
diff_x = sym.diff(function, x)
diff_y = sym.diff(function, y)
grad_vec = np.array([eval_(diff_x, [x_,y_]), eval_(diff_y, [x_, y_])], dtype=float)
return grad_vec, [diff_x, diff_y]
def gradient_descent(fun, init_point, lr_rate =1e-2, epsilon=1e-5):
cnt = 0
val = init_point
diff, _ = func_gradient(fun, val)
while np.linalg.norm(diff) > epsilon:
val = val - lr_rate*diff
diff, _ = func_gradient(fun, val)
cnt += 1
print(f"함수 : {fun(val)[1]}, 연산횟수: {cnt}, 최소점 : ({val}, {fun(val)[0]})")
pt = [np.random.uniform(-2,2), np.random.uniform(-2,2)]
gradient_descent(fun=func_multi, init_point=pt)
경사하강법으로 선형회귀 계수 구하기
선형 모델을 이용해서 분석을 할 경우 역행렬을 이용해 분석할 수 있지만 선형 모델이 아닌경우 역행렬을 이용한 분석을 할 수 없는데 이럴 경우 경사하강법을 사용해 분석을 할 수 있다. 선형 회귀식의 목적식은
\[||{y} - {X}\beta||_{2}\]이고 이를 최소화하는 $\beta$를 찾아야한다. 따라서 다음과 같은 그레디언트 벡터를 구해야한다.
\[{\nabla}_{\beta}||{y}-{X}\beta||_{2} = (\partial_{\beta_{1}}||{y}-{X}\beta||_{2},...,\partial_{\beta_{d}}||{y}-{X}\beta||_{2})\]목적식을 $\beta$로 미분한 다음에 주어진 벡터에서 미분값을 빼주면 경사하강법을 사용해 최소해를 구할 수 있다. 아래식에서 .k는 X의 전치행렬의 k번째 열을 의미
\[\nabla_{\beta_{k}}||\textbf{y}-\textbf{X}\beta||_{2} = \nabla_{\beta_{k}}\sqrt{\frac{1}{n}\varSigma(\textbf{y}_{i}-\Sigma\textbf{X}_{ij}\beta_{j})^2} \\=-\frac{\textbf{X_{.k}^T}(\textbf{y}-\textbf{X}\beta)}{n||\textbf{y}-\textbf{X}\beta||_{2}}\]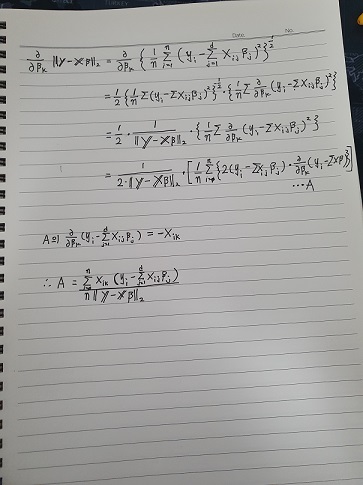
k번 베타의 식은 위와 같으므로 그레디언트 벡터는 다음과 같이 된다.
\[\nabla_{\beta}||\textbf{y}-\textbf{X}\beta||_{2} = (\partial_{\beta_{1}}||\textbf{y}-\textbf{X}\beta||_{2},...,\partial_{\beta_{d}}||\textbf{y}-\textbf{X}\beta||_{2})\\= (-\frac{\textbf{X_{.1}^T}(\textbf{y}-\textbf{X}\beta)}{n||\textbf{y}-\textbf{X}\beta||_{2}},...,-\frac{\textbf{X_{.d}^T}(\textbf{y}-\textbf{X}\beta)}{n||\textbf{y}-\textbf{X}\beta||_{2}})\\=-\frac{\textbf{X^T}(\textbf{y}-\textbf{X}\beta)}{n||\textbf{y}-\textbf{X}\beta||_{2}}...행렬로 표시\]\({X}\beta\) 를 계수 $\beta$에 대해 미분한 결과인 ${X}^T$만 곱해지는 것이다.
이전 경사하강법 알고리즘과 마찬가지로 다음 $\beta$는 현재 $\beta$에서 그레디언트 벡터를 빼준값이 된다.
\[\beta^{(t+1)} = \beta^{(t)}-\lambda\nabla_{\beta}||{y}-{X}\beta^{(t)}||\] \[\beta^{(t+1)} = \beta^{(t)}+ \frac{\lambda}{n}\frac{X^T({y}-{X}\beta^{(t)})}{||{y}-{X}\beta^{(t)}||}\]위의 식은 \(||{y}-{X}\beta||_{2}\) 를 최소화 하는 베타를 구하기위해 계산한 그레디언트 벡터인데
\(||{y}-{X}\beta||_{2}\) 이 아니라 \(||{y}-{X}\beta||^2_{2}\) 를 최소화 하면 식을 아래식처럼 더 단순화 할 수 있다.
\[\beta^{(t+1)} = \beta^{(t)} +\frac{2\lambda}{n}{X}^T({y}-{X}\beta^{(t)})\]1
2
3
4
5
6
7
# Input : X, y, lr, T, Output : beta
# lr : 학습률, T: 학습 횟수
for t in range(T):
error = y - X @ beta
grad = - transpose(X) @ error
beta = beta - lr * grad
경사하강법의 한계
이론적으로 경사하강법은 미분 가능하고 convex(볼록)한 함수에 대해서 적절한 학습률, 학습횟수를 선택했을 때 수렴이 보장된다. 특히 선형 회귀의 경우 목적식이 L2 norm은 회귀계수 $\beta$에 대해 볼록함수 이기 때문에 충분히 반복하면 수렴이 보장된다.
하지만 비선형회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지는 않는다.
확률적 경사하강법(SGD)
모든 데이터를 사용해서 업데이트 하는것이 아닌 한개 또는 일부의 데이터만 활용해 Gradient를 계산해 업데이트 하는방법이다. non-convex목적식은 SGD를 통해 최적화 할 수 있다. 그렇다고 SGD가 만능은 아니다 하지만 딥러닝의 경우 SGD가 경사하강법보다 실증적으로 더 낫다고 검증되었다.
Gradient를 계산할 때 사용되는 일부의 데이터를 mini batch라고 한다(mini batch SGD).
SGD 원리
SGD는 데이터의 일부를 가지고 패러미터를 업데이트하기 떄문에 연산자원을 좀 더 효율적을 활용할 수 있다. 전체 데이터 $({X},{Y})$를 사용하지않고 미니배치$({X}{(b)},{Y}{(b)})$를 사용하므로
$\beta^{(t+1)} = \beta^{(t)} +\frac{2\lambda}{n}{X}^T({y}-{X}\beta^{(t)})$ 식이 \(\beta^{(t+1)} = \beta^{(t)} +\frac{2\lambda}{b}{X}_{(b)}^T({y}_{(b)}-{X}_{(b)}\beta^{(t)})\) 처럼 되어 $O(d^2n)$의 복잡도가 $O(d^2b)$로 변하게 된다(연산량이 b/n으로 감소).
SGD의 경우 기존 경사하강법과 똑같은 결과를 도출할 수 없지만 확률적으로 기대값과 매우 유사한 결과가 나온다.
매번 반복마다 미니배치를 변경하며 하기때문에 목적함수가 달라져 곡선 모양이 달라진다. 경사하강법의 문제였던 극소값이 아닌데 0인지점을 탈출할 수 있다.
확률적 경사하강법의 원리 : 하드웨어
경사하강법을 사용하기에는 데이터의 크기도 크고, 양도 너무 많아 하드웨어 적으로 불가능한 경우가 많다. 하지만 확률적 경사하강법을 사용하게되면 데이터중 일부의 데이터셋(미니배치로 쪼갠 데이터)만 사용하여 연산하기 때문에 좀더 빠르고 하드웨어 한계를 극복할 수 있다.
SGD와 최적화 관련 링크
http://shuuki4.github.io/deep learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
https://hyunw.kim/blog/2017/11/01/Optimization.html
https://deepestdocs.readthedocs.io/en/latest/002_deep_learning_part_1/0021/